本文分析仅代表个人看法,如有错误请指教,好的项目值得深入,如果你也对LLM + Fuzzer感兴趣,CKGFuzzer是个不错的研究项目。
本文 Fuzz 针对库函数,实现细节分析的项目基于CKGFuzzer,该项目的论文即将要发表于2025年ICSE会议的论文CKGFuzzer,它通过结合代码知识图谱,让大语言模型可以更加高效且准确地生成模糊驱动器。
[出自:jiwo.org]
论文地址:CKGFuzzer: LLM-Based Fuzz Driver Generation Enhanced By Code Knowledge Graph
项目地址:security-pride/CKGFuzzer: CKGFuzzer: LLM-Based Fuzz Driver Generation Enhanced By Code Knowledge Graph
项目详细注释+Patch版本:Kernel/CKGFuzzer_mowen注释版 at master · mowenroot/Kernel
作者二开版本:mowenroot/AiLibFuzzer: LLM + Fuzzer
CKGFuzzer是一个将多智能体系统与代码知识图谱相结合的模糊驱动器生成框架,其目标是针对API组合生成高效的模糊驱动器,以提升模糊测试的质量和覆盖率。
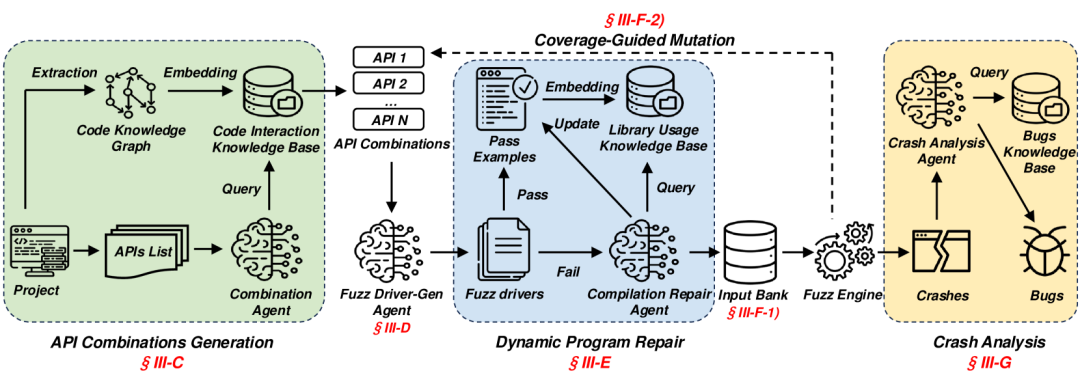
大致工作流:
1、解析被测目标及其库 API,提取并嵌入代码知识图谱,包括解析抽象语法树,提取数据结构、函数签名、调用关系等关键信息。
2、查询代码知识图谱的 API 组合,关注那些具有调用关系的 API,生成相应的模糊驱动器。
3、编译生成的模糊驱动器,并且通过一个动态更新的库使用情况,修复出现的编译错误。
4、执行编译成功的模糊驱动器,监控库文件的代码覆盖率,对未能覆盖的新路径 API 组合进行变异,迭代该过程并持续进行。
5、使用链式推理分析在模糊测试过程中产生的崩溃,参考包含了真实 CWE 相关的源码示例,来验证这些崩溃的有效性。
CKGFuzzer好处显而易见,优点也很多,相比于现有的方法(如PromptFuzz)通过不同的API变异组合利用LLM生成模糊驱动器,甚至手动编码,CKGFuzzer能够基于代码知识图的LLM驱动的模糊驱动器代理,指导 LLM 为模糊驱动器生成更高质量的 API 组合和基于覆盖引导的变异。
但是详细分析完也是存在一定缺点的:
1、使用的一些库是相对老的、codeql也是基于老版本,ql采用老版本编写的。
2、文件目录处理不清晰,代码和项目会混淆在一起,如果你不是很熟悉该项目,可能会被他的文件夹搞混。
3、使用LLM时确实采用了记忆的功能,但是没有切片的处理,在实际测试中,利用LLM生成 API 描述信息的时候,要发送的信息量太大,会导致tokens不足。
4、项目存在一定的BUG,在本文搜索Patch可以看到,其实也不能算是BUG,只是在测试中,环境不一致导致的不兼容。
5、多组API时,采用单进程进行Fuzz,耗时会成倍的增加,这里是可以采用多线程处理的,即使python有Gil锁。也能大幅度提升效率。
代码执行流程,官方提供了三步骤:
1、repo
从 Target 库中提取信息
python repo.py --project_name {project} --shared_llm_dir /docker_shared --saved_dir /fuzzing_llm_engine/external_database/{project}/codebase --src_api --call_graph
2、preproc
构建外部知识库
python preproc.py --project_name {project} --src_api_file_path /fuzzing_llm_engine/external_database/{project}
3、fuzzing
运行模糊测试进程
python fuzzing.py --yaml /fuzzing_llm_engine/external_database/{project}/config.yaml --gen_driver --summary_api --check_compilation --gen_input
整体流体大致如下,这里做了简化实际执行没有这么简单,但是总体逻辑大致一样:
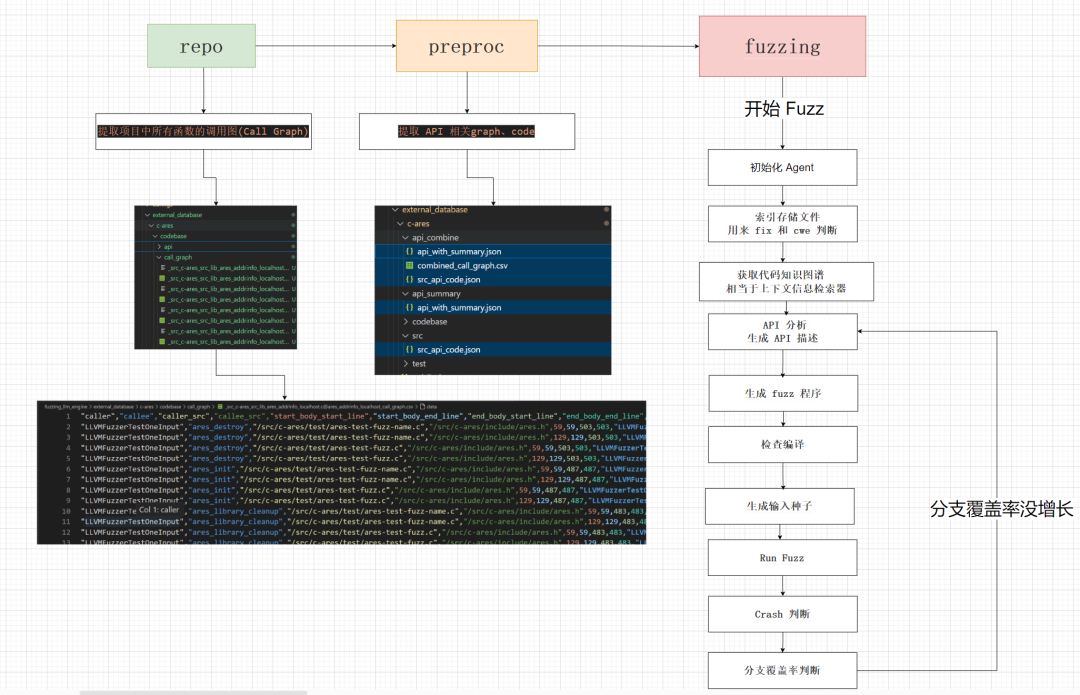
分析也采用三步走,下面开始万字的详细分析底层实现,因为CKGFuzzer的核心就是LLM操作生成高质量的target_fuzz和Fuzz的覆盖率回调的API优化,所有会针对相关操作细致化分析,其他部分会粗略过。
repo
在10线程下整个流程大概花了 3小时40分钟

文件位于
fuzzing_llm_engine/repo/repo.py

1、add_codeql_to_path()
添加codeql到环境变量中
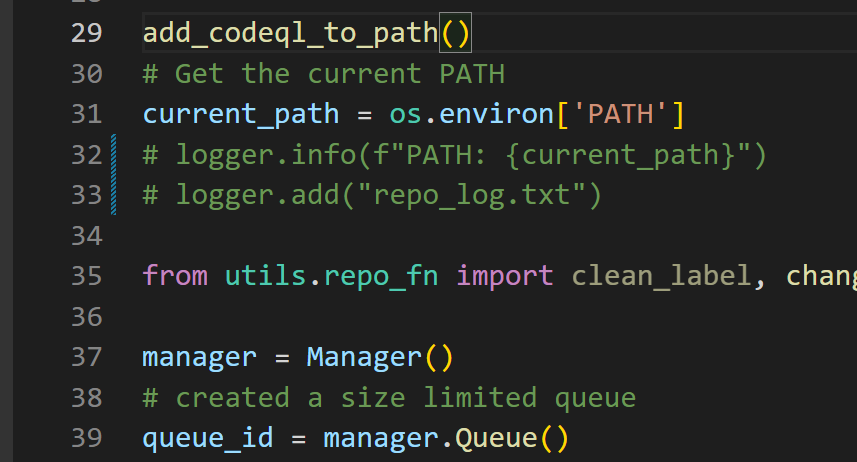
这里有个小bug,已经修复
CODEQL_DIR = os.path.abspath("../../") # Adjust the number of parents based on submodule depth CODEQL_PATH=f"{CODEQL_DIR}/docker_shared/codeql" def add_codeql_to_path(): codeql_path = CODEQL_PATH current_path = os.environ.get('PATH', '') # print(f"Current PATH: {current_path}") # Check if CodeQL path is already in PATH1 if codeql_path not in current_path: # Adding CodeQL to PATH os.environ['PATH'] += os.pathsep + codeql_path print(f"CodeQL has been added to PATH. New PATH: {os.environ['PATH']}") else: print("CodeQL is already in the PATH.")
Patch
原程序只有../ ,会导致定位不到外层的 docker_shared , 只会在fuzzing_llm_engine
2、main()
1.setup_parser()
获取传入参数
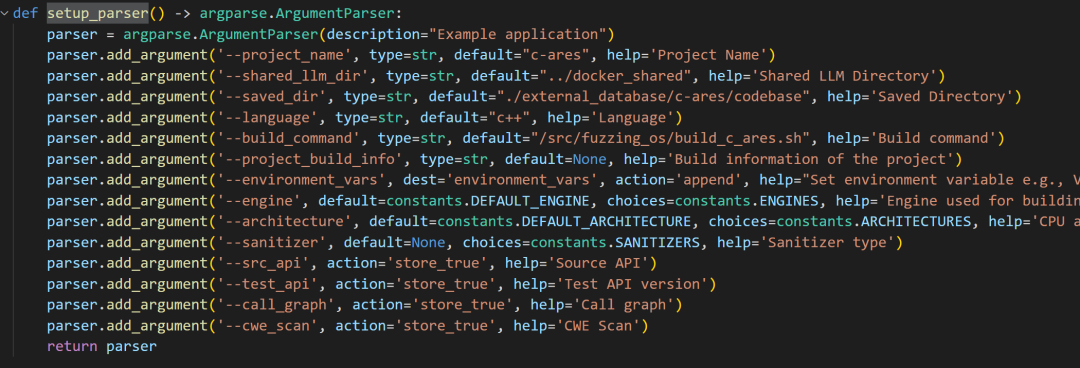
2.RepositoryAgent()
初始化该RepositoryAgent类,完成以下事情
class RepositoryAgent: def __init__(self, args: Dict = None): """ Initializes the PlanningAgent with the extracted API information. Args: api_info (Dict, optional): Extracted API information to be used for planning fuzzing tasks. Defaults to None. """ #super().__init__() self.args = args self.shared_llm_dir = args.shared_llm_dir self.src_folder = f'{args.shared_llm_dir}/source_code/{args.project_name}' self.queryes_folder = f'{args.shared_llm_dir}/qlpacks/cpp_queries/' self.database_db = f'{args.shared_llm_dir}/codeqldb/{args.project_name}' self.output_results_folder = f'{args.saved_dir}' # 检查输出目录 check_create_folder(self.output_results_folder) # 检查代码库是否存在 self.init_repo()
「1」维护该类中的字段:
shared_llm_dir -> docker共享目录 "docker_shared" src_folder -> 项目源码目录 ,源码目录存在于 shared_llm_dir/source_code/{project_name} queryes_folder -> 查询文件夹 database_db -> codeql 数据库位置 output_results_folder -> 输出目录 , 对应 args.saved_dir
「2」调用check_create_folder() 检查输出目录是否存在,如果不存在则新建:
def check_create_folder(folder_path): """ Check if the folder exists, if not create it. """ if not os.path.exists(folder_path): os.makedirs(folder_path) print(f"Created folder: {folder_path}")
「3」调用self.init_repo()使用提供的参数初始化存储库。
◆将repo添加到数据库代码中。
◆提取API信息。
init_repo
「1」init_repo()会先检查codeqldb是否存在,以.successfully_created文件来判断,如果该文件存在则表示codeqldb存在。如果不存在调用self._add_local_repo_to_database()开始创建database。
「2」 如果当 src_folder 源码目录不存在时,会调用self.copy_source_code_fromDocker(),从docker中复制数据出来。
def init_repo(self) -> List[str]: """ Initializes the repository with the provided arguments. 1. Add the repo to the database codeql. 2. Extract API Info. """ # 检查codeqldb是否存在 if os.path.isfile(f'{args.shared_llm_dir}/codeqldb/{args.project_name}/.successfully_created'): # logger.info(f"Database for {args.project_name} already exists.") pass
# print(f"Database for {args.project_name} already exists.") else: # 如果不存在,开始创建database self._add_local_repo_to_database(self.args) if not os.path.isdir(f'{self.src_folder}'): logger.info(f"{args.project_name} does not exist.") self.copy_source_code_fromDocker()
_add_local_repo_to_database
def _add_local_repo_to_database(self, args: Dict) -> None: # 获取用户名 USER_NAME = getpass.getuser() # 获取项目目录 project_dir = os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), 'projects', args.project_name) # 目录指向 fuzzing_llm_engine/projects/* /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/projects/c-ares logger.error(f"mowen: {project_dir}") dockerfile_path = os.path.join(project_dir, 'Dockerfile') # 目录下面包括 build.sh dockerfile project.yaml if not os.path.exists(dockerfile_path): raise FileNotFoundError(f"Dockerfile not found at {dockerfile_path}") # image_name == c-ares_base_image image_name = f'{args.project_name}_base_image' build_command = f'docker build -t {image_name} -f {dockerfile_path} {project_dir}' # 准备docker启动命令 -t 指定构建docker的tag -f 指定dockerfile的目录 最后跟上项目dir # 构建docker镜像 try: subprocess.run(build_command, shell=True, check=True) except subprocess.CalledProcessError as e: print(f"Failed to build Docker image: {e}") return # Prepare the CodeQL command # 创建 codql 数据库 codeql_command = f'/src/fuzzing_os/codeql/codeql database create /src/fuzzing_os/codeqldb/{args.project_name} --language={args.language}' if args.language in ['c', 'cpp', 'c++', 'java', 'csharp', 'go', 'java-kotlin']: codeql_command += f' --command="/src/fuzzing_os/wrapper.sh {args.project_name}"' # Run the Docker container with the CodeQL command command = [ 'docker', 'run', '--rm', '-v', f'{args.shared_llm_dir}:/src/fuzzing_os', # 映射卷,把本地的 shared_llm_dir 挂载到容器中的 /src/fuzzing_os '-t', image_name, '/bin/bash', '-c', codeql_command ] # 在 docker中执行 codeql 指令 result = subprocess.run(command, capture_output=True, text=True) # 更改文件夹所有者,因为docker中是root用户,映射出来有问题 change_folder_owner(f"{args.shared_llm_dir}/change_owner.sh", f'{args.shared_llm_dir}/codeqldb/{args.project_name}', USER_NAME) if f"Successfully created database at /src/fuzzing_os/codeqldb/{args.project_name}" in result.stdout: with open(f'{args.shared_llm_dir}/codeqldb/{args.project_name}/.successfully_created', 'w') as f: f.write('') logger.info(result.stdout) logger.info(f"Confirmed Successfully created database at /src/fuzzing_os/codeqldb/{args.project_name}") else: print(result.stdout) print(result.stderr) assert False, f"Failed to create database at /src/fuzzing_os/codeqldb/{args.project_name}"
「1」 使用 getpass.getuse() 获取当前用户名,用于后面更改docker 中的文件所有者,因为文件映射中docker权限为root。
「2」 获取项目目录, 目录指向fuzzing_llm_engine/projects/{project_name},该项目的目录下面包括build.sh dockerfile project.yaml三个文件,用于构建环境使用。
build.sh 用于编译项目 dockerfile 用于拉取项目所需要的docker project.yaml 设置基础的配置信息
「3」 维护 image_name 、 build_command变量。 image_name 为 docker的img名称,一般为
"项目name"+"_base_image",build_command 为 构建 docker 的命令。然后执行 build_command 开始构建 docker 镜像。
未检查 docker_img 是否存在,这里增加检测
Isin_dockerimg = False client = docker.from_env() print(client.images.list()) for img in client.images.list(): for tag in img.tags: print(img,tag,image_name) if tag.startswith(image_name): logger.info(f"Image {image_name} already exists.") Isin_dockerimg = True break if Isin_dockerimg: break
build_command = f'docker build -t {image_name} -f {dockerfile_path} {project_dir}' #准备docker启动命令 -t 指定构建docker的tag -f 指定dockerfile的目录 最后跟上项目dir
构建可以成功,但是可能会出现两个警告,

警告原因因为,WORKDIR c-ares未使用绝对目录,建议使用绝对目录。
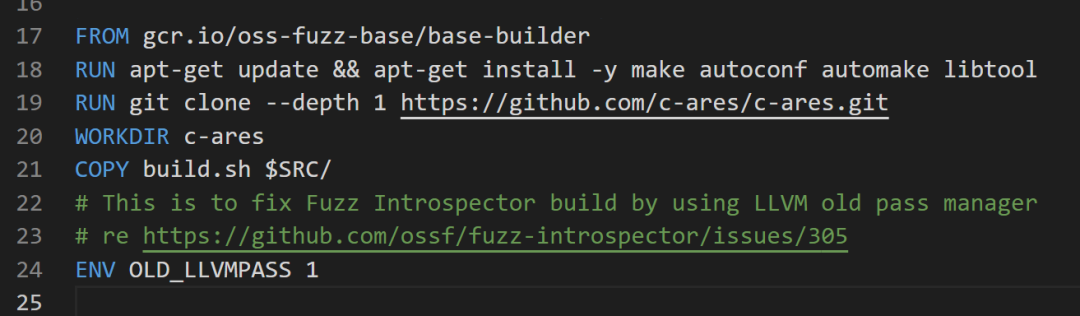
ENV OLD_LLVMPASS 1的设置 应该为ENV OLD_LLVMPASS=1
「4」 在docker中 创建codql数据库,通过以下命令拉起docker 并构建codeql数据库,这里执行语句带入了我本机的目录,方便理解。并在创建完 codeql database 后,在docker_shared/codeqldb/项目目录下 创建 .successfully_created 文件来表示数据库创建成功。
可能会因为 /usr/local/bin/compile: line 27: FUZZING_LANGUAGE: unbound variable 报错 ,

需要加上 -e FUZZING_LANGUAGE={args.language}
这里为了方便调试我使用 docker保活,然后进去看docker配置
这个时候可能还有问题,提示没有codeql这个目录,这里我直接用脚本添加,当然也可以手动添加。

docker run --rm -v /home/mowen/CKGFuzzer_mowen/docker_shared:/src/fuzzing_os -e FUZZING_LANGUAGE=c -t c-ares_base_image
docker run --rm -v /home/mowen/CKGFuzzer_mowen/docker_shared:/src/fuzzing_os -e FUZZING_LANGUAGE=c -it c-ares_base_image bash
docker run --rm -v /home/mowen/CKGFuzzer_mowen/docker_shared:/src/fuzzing_os -e FUZZING_LANGUAGE=c -t c-ares_base_image /bin/bash -c /src/fuzzing_os/codeql/codeql database create /src/fuzzing_os/codeqldb/c-ares --language=c --command="/src/fuzzing_os/wrapper.sh c-ares"
主要做了,-v 映射文件夹到docker,-e 指定了环境变量, -t 指定启动镜像, -c 执行了codeql 创建数据库语句。
在使用codeql 创建数据库时,编译语句使用/src/fuzzing_os/wrapper.sh c-ares。
wrapper.sh
wraper主要负责 定位到项目源代码处,并对 build.sh 脚本做了检查,然后运行 build.sh 脚本。
# 切换到目标项目目录,$1 是脚本的第一个参数,表示项目的名称或路径 cd /src/$1 # 定义 build.sh 脚本的路径 script_path=/src/build.sh
# 检查 build.sh 文件是否存在 if [ ! -f "$script_path" ]; then
# 如果文件不存在,输出错误信息并退出脚本,返回状态码为 1 echo "Error: File '$script_path' does not exist." exit 1 fi
# 使用 grep 命令检查 build.sh 文件中是否包含命令 "bazel_build_fuzz_tests" if grep -q "bazel_build_fuzz_tests" "$script_path"; then
# 如果找到该命令,输出提示信息 echo "The command 'bazel_build_fuzz_tests' is found in '$script_path'."
# 将 /src/fuzzing_os/bazel_build 文件复制到 /usr/local/bin/ 目录下 cp /src/fuzzing_os/bazel_build /usr/local/bin/
# 使用 sed 命令将 build.sh 文件中的 "exec bazel_build_fuzz_tests" 替换为 "exec bazel_build" sed -i 's/exec bazel_build_fuzz_tests/exec bazel_build/g' $script_path
# 注释掉以下行,表示可以选择替换 script_path 的值为另一个脚本路径(当前未启用) # script_path=/src/fuzzing_os/bazel_build.sh else
# 如果未找到该命令,输出提示信息 echo "The command 'bazel_build_fuzz_tests' is not found in '$script_path'." fi
# 执行 build.sh 脚本 bash $script_path # 强制将脚本的退出状态码设置为 0,无论前面的命令执行结果如何 exit 0
build.sh
就是针对每个项目进行客制化编译了
# Build the project.
# 运行 buildconf 脚本,准备构建环境 ./buildconf # 配置项目,启用调试模式并禁用测试 ./configure --enable-debug --disable-tests # 清理之前的构建结果 make clean
# 使用所有可用的 CPU 核心进行并行编译,并输出详细的构建信息 make -j$(nproc) V=1 all
# Build the fuzzers. # 使用 C 编译器编译模糊测试源文件 ares-test-fuzz.c,生成目标文件 $CC $CFLAGS -Iinclude -Isrc/lib -c $SRC/c-ares/test/ares-test-fuzz.c -o $WORK/ares-test-fuzz.o
# 使用 C++ 编译器将目标文件链接成可执行的模糊测试程序 $CXX $CXXFLAGS -std=c++11 $WORK/ares-test-fuzz.o \ -o $OUT/ares_parse_reply_fuzzer \
# 输出文件路径和名称 $LIB_FUZZING_ENGINE \
# 链接模糊测试引擎库 $SRC/c-ares/src/lib/.libs/libcares.a
# 链接 c-ares 库
# 同样地,编译另一个模糊测试源文件 ares-test-fuzz-name.c $CC $CFLAGS -Iinclude -Isrc/lib -c $SRC/c-ares/test/ares-test-fuzz-name.c \ -o $WORK/ares-test-fuzz-name.o
# 将第二个模糊测试程序链接成可执行文件 $CXX $CXXFLAGS -std=c++11 $WORK/ares-test-fuzz-name.o \ -o $OUT/ares_create_query_fuzzer \
# 链接模糊测试引擎库 $SRC/c-ares/src/lib/.libs/libcares.a
# 链接 c-ares 库
# Archive and copy to $OUT seed corpus if the build succeeded. zip -j $OUT/ares_parse_reply_fuzzer_seed_corpus.zip $SRC/c-ares/test/fuzzinput/* zip -j $OUT/ares_create_query_fuzzer_seed_corpus.zip \ $SRC/c-ares/test/fuzznames/*
3.extract_api_from_head
当 --src_api 存在时,会调用extract_api_from_head()

def extract_api_from_head(self):
# 判断项目源码是否存在,直接从docker映射出来,相对路径为 docker_shared/source_code/{project_name} if not os.path.isdir(self.src_folder): logger.info(f"{self.src_folder} does not exist.")
# 如果不存在需要从 docker 中 copy 出来 self.copy_source_code_fromDocker() logger.info(f"Extracting API information from the source code. {self.src_folder}")
# src_dic 为项目中的头文件 + c/cpp文件
# test_dic 为项目中的测试文件 src_dic, test_dic = find_cpp_head_files(self.src_folder) logger.info(f"Number of source files: {len(src_dic['src'])}") logger.info(f"Number of header files: {len(src_dic['head'])}")
# 如果 头文件不存在 if not src_dic['head']: logger.warning("No header files found!")
# 遍历所有文件并打印文件路径 for root, dirs, files in os.walk(self.src_folder): logger.debug(f"Directory: {root}") for file in files: logger.debug(f"File: {os.path.join(root, file)}") logger.info("Extracting API information from the source code.") logger.debug(f"src_dic -> {src_dic}")
# 提取API信息 result_src = self._extract_API(src_dic) logger.info("Extracting API information from the test code.") result_test= self._extract_API(test_dic) logger.info(f"Store API to {self.output_results_folder}/api/") os.makedirs(f'{self.output_results_folder}/api', exist_ok=True)
# 保存文件列表 json.dump(result_src, open(f'{self.output_results_folder}/api/src_api.json', 'w'), indent=2) json.dump(result_test, open(f'{self.output_results_folder}/api/test_api.json', 'w'), indent=2) return result_src, result_test
「1」先判断项目源码是否存在,如果不存在需要从docker中复制出来
「2」调用find_cpp_head_files()遍历并收集项目下面的所有 c/cpp 和 head文件,src_dic 为 项目中的头文件 + c/cpp文件,test_dic 为 项目中的测试文件 。
「3」调用_extract_API()分别为两个文件字典提取API信息,最后保存该文件列表{self.output_results_folder}/api/到json中。
find_cpp_head_files()
「1」遍历项目中的所有文件,搜集 头文件和 c/cpp 文件,并区分是否包含test,区别是否包含test使用check_path_test()函数。
def find_cpp_head_files(directory): source_files = {"src": [], "head": []}
test_files = {"src": [], "head": []}
src_extensions = {'.c', '.cpp', '.c++', '.cxx', '.cc', '.C'}
head_extensions = {'.h', '.hpp', '.h++', '.hxx', '.hh', '.H', '.inl', '.inc'}
logger.info(f"Searching for files in: {directory}")
# 遍历文件夹 (当前目录,子目录,文件)
for root, _, files in os.walk(directory):
for file in files:
# 获取当前文件的路径
file_path = os.path.join(root, file)
# 拆分文件名和后缀
_, ext = os.path.splitext(file)
logger.debug(f"Processing file: {file_path}")
# 搜集 头文件和 c/cpp 文件,并区分是否包含test
if ext in src_extensions:
# check_path_test 检测文件名是否包含test
if check_path_test(file_path):
test_files["src"].append(file_path)
logger.debug(f"Added to test_src: {file_path}")
else:
source_files["src"].append(file_path)
logger.debug(f"Added to source_src: {file_path}")
elif ext in head_extensions:
if check_path_test(file_path):
test_files["head"].append(file_path)
logger.debug(f"Added to test_head: {file_path}")
else:
source_files["head"].append(file_path)
logger.debug(f"Added to source_head: {file_path}")
logger.info(f"Found {len(source_files['src'])} source files and {len(source_files['head'])} header files.")
logger.info(f"Found {len(test_files['src'])} test source files and {len(test_files['head'])} test header files.")
# 返回文件
return source_files, test_files
_extract_API
「1」利用上一步find_cpp_head_files()收集的文件进行遍历,这里做了一个兼容性读取文件内容。
「2」利用CppParser.split_code()提取文件中的相应结构,is_return_node: 决定是否返回抽象语法树(AST)节点对象(True 返回 AST 节点,False 返回可序列化信息,如字符串 + 位置)。
◆fn_def_list: 函数定义列表
◆fn_declaraion: 函数声明列表
◆class_node_list: 类定义
◆struct_node_list: 结构体定义
◆include_list: 包含的头文件
◆global_variables: 全局变量
◆enumerate_node_list: 枚举类型b
「3」将返回的数据保存到同目录的{src}.debug.json文件中。
def _extract_API(self, src_dic):
# 嵌套字典
result = collections.defaultdict(dict)
for k in ['src', 'head']:
logger.info(f"Processing {k} files")
# 遍历所有 src/head 文件
for src in src_dic[k]:
logger.info(f"Processing file: {src}")
# 读取文件内容,这里做了兼容性处理,如果文件编码无法识别,则尝试使用 latin1 编码读取
try:
with open(src, 'r', encoding='utf-8') as file:
code = file.read()
except UnicodeDecodeError:
with open(src, 'rb') as file:
raw = file.read()
detected = chardet.detect(raw)
encoding = detected['encoding']
try:
code = raw.decode(encoding)
except:
logger.error(f"Failed to decode {src} with detected encoding {encoding}. Skipping this file.")
continue try: ''' fn_def_list: 函数定义列表 fn_declaraion: 函数声明列表 class_node_list: 类定义 struct_node_list: 结构体定义 include_list: 包含的头文件 global_variables: 全局变量 enumerate_node_list: 枚举类型 ''' # 提取c/cpp中的相应结构,
# is_return_node: 是否返回抽象语法树(AST)节点对象(True 返回 AST 节点,False 返回可序列化信息,如字符串 + 位置)
fn_def_list, fn_declaraion, class_node_list, struct_node_list, include_list, global_variables, enumerate_node_list = CppParser.split_code(code, is_return_node=False)
result[k][src] = { 'fn_def_list': fn_def_list, 'fn_declaraion': fn_declaraion, 'class_node_list': class_node_list, 'struct_node_list': struct_node_list, 'include_list': include_list, "global_variables": global_variables, "enumerate_node_list": enumerate_node_list } l
ogger.info(f"Successfully processed {src}")
logger.info(f"Found {len(fn_def_list)} function definitions, {len(fn_declaraion)} function declarations, {len(class_node_list)} classes, {len(struct_node_list)} structs") debug_output_path = f'{src}.debug.json' with open(debug_output_path, 'w') as f: json.dump(result[k][src], f, indent=2) logger.info(f"Debug output written to {debug_output_path}") except Exception as e: logger.error(f"Error processing {src}: {str(e)}") continue logger.info(f"Finished processing all files. Found data for {len(result['src'])} source files and {len(result['head'])} header files.")
return result
4.extract_src_test_api_call_graph()
如果制定了call_graph则会调用extract_src_test_api_call_graph(),你会发现还会调用extract_api_from_head(),所以指定了call_graph就可以不用使用--src_api。
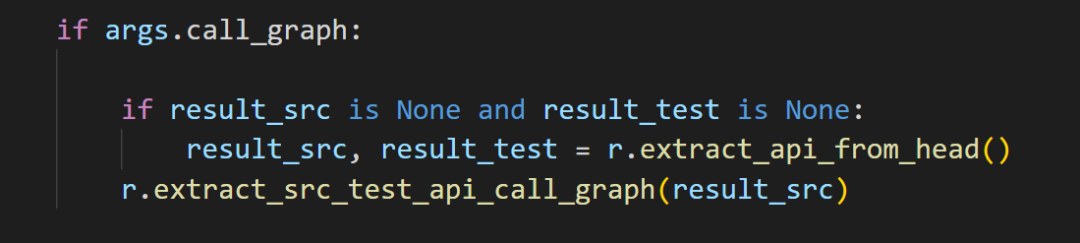
报错在运行 CodeQL 查询时,缺少了一个关键的依赖包:codeql/cpp-all,而且没有对应的 lock 文件来自动安装。 
查看了qlack.ymal的格式使用的是libraryPathDependencies,是很老版本使用的,所以这里需要把SDK+引擎都降级为 v2.7.3
引擎地址:Releases · github/codeql-cli-binaries
SDK地址:Release codeql-cli/v2.7.3 · github/codeql
当 SDK+引擎 都降级后才能使用源代码正常执行,否则需要重写 ql 很麻烦。

extract_src_test_api_call_graph
作用:提取源码和测试代码中的 API 调用图(Call Graph)
# read the function name and its source code name from the returned dict of extract_api_from_head def extract_src_test_api_call_graph(self, data: Dict, pool_num=10) -> Dict: """ 提取源码和测试代码中的 API 调用图(Call Graph) 支持多线程并行提取,每个线程用一份数据库副本。 ToDO: multple thread SUPPORT, need to keep the copy database for each thread Extracts the source and test API information from the repository. """ logger.info("Extracting source and test API information from the repository.") src_api = [] # 每个文件中提取出 fn_def_list(函数定义列表) for src_file in data['src']: fn_def_list = data['src'][src_file]['fn_def_list'] # 遍历函数定义,取出每个函数的名字 for item in fn_def_list: fn_name = item['fn_meta']['identifier'] # 原始路径替换为容器内的路径 /src/,供 docker 中的 codeql 使用 src_api.append((fn_name, src_file.replace(f'{args.shared_llm_dir}/source_code/', '/src/'))) # (函数名, 文件路径) example -> ('jni_get_class', '/src/c-ares/src/lib/ares_android.c') ''' 构造一个任务列表 eggs,包含每个函数所需的信息 [函数名, 文件路径, CodeQL 数据库路径, 输出结果文件夹路径, LLM 工作目录路径] ''' eggs = [ (api[0].strip(), api[1].strip(), self.database_db, self.output_results_folder, self.shared_llm_dir) for api in src_api ] logger.info(f"Total number of API to be processed: {len(eggs)}") logger.info("Copy Database for each thread.") # 多线程处理,为每个线程拷贝一份数据库 # docker_shared/codeqldb/project ->(copy) docker_shared/codeqldb/project_n for i in tqdm(range(pool_num)): shutil.copytree(self.database_db, f'{self.database_db}_{i}', dirs_exist_ok=True) queue_id.put(i) # 并发运行 handle_extract_api_call_graph_multiple_path 函数 with Pool(pool_num) as pool: results = list(tqdm(pool.imap(RepositoryAgent.handle_extract_api_call_graph_multiple_path, eggs), total=len(eggs), desc='Processing transactions')) # 删除拷贝用的临时数据库 for i in range(pool_num): shutil.rmtree(f'{self.database_db}_{i}')
「1」根据之前extract_api_from_head()提出出来的api文件,把每个文件中的fn_def_list(函数定义列表)提取出来。
「2」构造一个任务列表 eggs,中包含每个函数所需的信息,[函数名,文件路径,CodeQL 数据库路径,输出结果文件夹路径,LLM 工作目录路径]
「3」因为整个项目太大了,使用codeql 提取出调用关系又慢,所以必须要使用多线程,使用多线程需要为每个线程拷贝一份数据库,然后并发运行 handle_extract_api_call_graph_multiple_path 函数,执行完后删除拷贝用的临时数据库。
handle_extract_api_call_graph_multiple_path
该函数作用主要就是_extract_call_graph()的封装
@staticmethod def handle_extract_api_call_graph_multiple_path(item): global queue_id pid = os.getpid() # Get the current process ID # 从 queue_id 队列中取出一个数据库副本编号(bid)。 bid = queue_id.get() logger.info(f"============================ {pid} Consuming {bid}") fn_name, fn_file_name, dbbase, outputfolder, shared_llm_dir = item # 调用 _extract_call_graph 方法执行 API 调用图提取逻辑 RepositoryAgent._extract_call_graph(shared_llm_dir, fn_name, fn_file_name, f"{dbbase}_{bid}", outputfolder, bid) queue_id.put(bid)
extract_call_graph.sh
做了一些初始化,核心语句就三句
# 复制查询模板到生成的查询文件 cp "$QUERY_TEMPLATE" "$QUERY" # 替换为实际函数名 sed -i "s/ENTRY_FNC/$fn_name/g" "$QUERY" # 执行CodeQL查询 codeql query run "$QUERY" --database="$dbbase" --output="$outputfile"
执行这个脚本后就可以使用 codeql 查询所有文件中的所有函数的调用关系以供后面输出fuzz的target文件。
#!/bin/bash # 立即退出脚本,如果任何命令返回非零状态 set -e # 获取当前脚本的完整路径 script_path=$(realpath "$0") # 提取脚本所在的目录路径 script_dir=$(dirname "$script_path") # 切换到脚本所在的工作目录 cd "$script_dir" # 从参数中获取函数名、文件路径、数据库路径、输出文件夹和进程ID fn_name=$1 # 函数名 fn_file=$2 fn_file="${fn_file//\//_}" # 文件路径(替换斜杠为下划线) dbbase=$3 # codeql数据库路径 outputfolder=$4 # 输出文件夹路径 pid=$5 # 进程ID # 打印相关信息 echo "Script Dir ====== $script_dir" echo "Database path: $dbbase" echo "Output folder: $outputfolder" echo "Process ID: $pid" # 检查输出文件夹是否存在,不存在则创建 [ -d "$outputfolder/call_graph" ] || mkdir -p "$outputfolder/call_graph" # 定义输出文件路径 outputfile="$outputfolder/call_graph/${fn_file}@${fn_name}_call_graph.bqrs" # 定义查询模板文件路径 QUERY_TEMPLATE="./extract_call_graph_template.ql" # 定义生成的查询文件名 QUERY="call_graph_${pid}.ql" # 打印信息:复制模板并生成查询文件 echo "Copying template and generating query file..." # 复制查询模板到生成的查询文件 cp "$QUERY_TEMPLATE" "$QUERY" # 使用sed命令将模板中的占位符ENTRY_FNC替换为实际函数名 sed -i "s/ENTRY_FNC/$fn_name/g" "$QUERY" # 打印信息:运行CodeQL查询 echo "Running query: codeql query run $QUERY --database=$dbbase --output=$outputfile" # 执行CodeQL查询 if codeql query run "$QUERY" --database="$dbbase" --output="$outputfile"; then # 如果查询成功,打印信息:转换BQRS文件为CSV echo "Query executed successfully. Converting BQRS to CSV." # 定义CSV输出文件路径 csv_output="${outputfile%.bqrs}.csv" # 将BQRS文件解码为CSV格式 if codeql bqrs decode --format=csv "$outputfile" --output="$csv_output"; then # 如果转换成功,打印信息 echo "BQRS file successfully converted to CSV: $csv_output" else # 如果转换失败,打印错误信息并退出 echo "Error converting BQRS to CSV" exit 1 fi else # 如果查询失败,打印错误信息并退出 echo "Error executing CodeQL query" exit 1 fi # 删除临时生成的查询文件 rm "$QUERY"
大致会类似执行以下语句
export database="/home/mowen/CKGFuzzer_mowen/docker_shared/codeqldb/c-ares_0" export outputfile="/home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/external_database/c-ares/codebase/call_graph/_src_c-ares_src_lib_ares_android.c@jni_get_class_call_graph.bqrs" codeql query run call_graph_0.ql --database="$dbbase" --output="$outputfile"
执行完成后 fuzzing_llm_engine/external_database/{项目名称}/call_garph 下会有 每个函数的调用关系的bqrs和csv。
preproc
用来构建外部知识库
文件位于 :./fuzzing_llm_engine/repo/preproc.py
main
if __name__ == "__main__": parser = setup_parser() args = parser.parse_args() src_api_file_path = args.src_api_file_path #"fuzzing_llm_engine/external_database/c-ares" combine_call_graph(src_api_file_path) extract_api_from_file(src_api_file_path) extract_fn_code(src_api_file_path)
「1」设置传参格式,project_name(项目文件名)、src_api_file_path(external_database/{项目名}的位置)
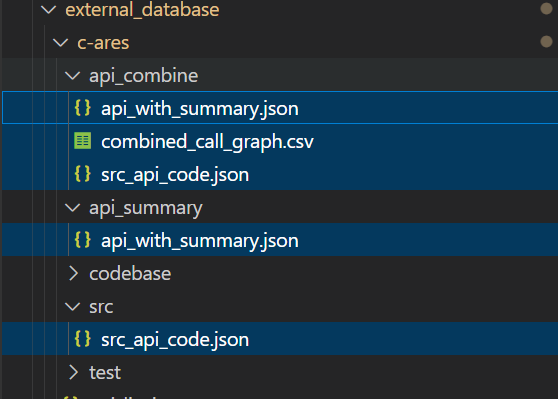
「2」通过用户指定的api_list使用三个函数进行聚合信息,combine_call_graph聚合graph关系,extract_api_from_file聚合 api 基本信息(函数名、函数所在文件),extract_fn_code聚合函数代码。
经过聚合后会在 api_combine 中产生三个对应的聚合文件。
setup_parser
就只有两个参数,一个项目名称,还有一个为上一步repo.py提取出来的api文件所在处()。

combine_call_graph
就是聚合作用,把用户指定的 api 所对应函数的调用关系全部聚合在一个新的文件中。
def combine_call_graph(src_api_file_path): # 获取用户提供的 api_list.json api_list_path=os.path.join(src_api_file_path, 'api_list.json') with open(api_list_path, 'r') as f: api_list = json.load(f) csv_folder_path = os.path.join(src_api_file_path, 'codebase/call_graph') csv_files = [] # 遍历 codebase/call_graph 文件夹中所有以 .csv 结尾的文件 # 根据用户提供的 api_list.json 来筛选出匹配的 CSV 文件 保存到 csv_files for file in os.listdir(csv_folder_path): if file.endswith('.csv'): # 通过特殊命名找到,api_name # api_name -> 文件中所有的函数命名 api_name = file.split('@')[-1].split("_call_graph")[0] if api_name in api_list: print(f"Found matching API: {api_name}") csv_files.append(os.path.join(csv_folder_path, file)) print(f"Number of matching CSV files: {len(csv_files)}") # 如果用户定义的 api 不存在,则返回None if not csv_files: print("No matching CSV files found. Check your api_list and csv_folder_path.") return None # 遍历需要的 CSV 文件,并读取到 data_frames 中 data_frames = [] for file in csv_files: df = pd.read_csv(file) # 读取 CSV 、返回值是 DataFrame if not df.empty: data_frames.append(df) else: print(f"Warning: Empty CSV file: {file}") if not data_frames: print("All CSV files are empty. Check your CSV files.") return None # 多个 DataFrame 对象合并成一个单一的 DataFrame # ignore_index=True 拼接时重新生成索引 combined_csv = pd.concat(data_frames, ignore_index=True) if combined_csv.empty: print("Combined DataFrame is empty. Check your CSV files and api_list.") else: print(f"Combined DataFrame shape: {combined_csv.shape}") print(combined_csv) # Create the 'api_combine' directory if it doesn't exist api_combine_dir = os.path.join(src_api_file_path, 'api_combine') if not os.path.exists(api_combine_dir): os.makedirs(api_combine_dir) # 将合并后的调用图数据(combined_csv)保存为一个新的 CSV 文件 combined_csv.to_csv(api_combine_dir+'/'+'combined_call_graph.csv', index=False)
「1」遍历codebase/call_graph文件夹中所有以.csv结尾的文件,根据用户提供的api_list.json来筛选出匹配的CSV文件。
「2」遍历匹配的CSV文件,通过pd库将多个csv 合并为一个并保存到api_combine/combined_call_graph.csv。
extract_api_from_file
也是聚合作用,与 combine_call_graph 不同的是,把之前提取的 api 信息进行聚合,聚合两个信息(函数名和函数所在的文件名)
def extract_api_from_file(src_api_file_path): api_list_path=os.path.join(src_api_file_path, 'api_list.json') api_summary_path=os.path.join(src_api_file_path, 'api_summary/api_with_summary.json') # 加载所有用户指定的 api with open(api_list_path, 'r') as f: api_list = json.load(f) # 加载之前提取的 api 信息 with open(src_api_file_path+"/codebase/api/src_api.json", 'r') as f: src_api_data = json.load(f) api_file_dict = {} api_cnt = 0 # 遍历非头文件获取所有函数名,判断是否属于 api_list ,属于则添加到 api_file_dict for key,value in src_api_data.items(): if key == "src": # src_key -> 文件路径 for src_key,src_value in value.items(): # api_file -> 文件名 api_file = src_key.split('/')[-1] #api_file_dict[api_file] = {} apis = {} for key,value in src_value.items(): # 只提取函数定义列表 if key == "fn_def_list": for api in value: api_dict = {} # 获取函数名 api_name = api["fn_meta"]["identifier"] if api_name == '': continue # 如果存在于 api列表中 则添加 if api_name in api_list: api_cnt += 1 apis[api_name] = '' if apis: api_file_dict[api_file] = apis print(f"Total number of APIs in {src_api_file_path}: {api_cnt}") # 聚合 api 保存到 api_summary.json # Check if the directory exists, if not create it os.makedirs(os.path.dirname(api_summary_path), exist_ok=True) # Check if the file exists, if not create it if not os.path.exists(api_summary_path): with open(api_summary_path, "w", encoding='utf-8') as f: json.dump(api_file_dict, f, indent=2, sort_keys=True, ensure_ascii=False) # Copy api_summary file to src_api_file_path/api_combine # 拷贝 api_summary.json 到 api_combine api_combine_dir = os.path.join(src_api_file_path, "api_combine") os.makedirs(api_combine_dir, exist_ok=True) shutil.copy2(api_summary_path, os.path.join(api_combine_dir, os.path.basename(api_summary_path))) print(f"Copied {api_summary_path} to {api_combine_dir}/{os.path.basename(api_summary_path)}") return api_file_dict
「1」遍历之前提取的 api 信息,根据用户提供的api_list.json来提取出 函数名、函数所在文件。
「2」聚合 api 信息保存到api_summary.json并拷贝至api_combine下, 现在api_combine目录下会有两个文件: graph 聚合、api 聚合。
extract_fn_code
也是聚合作用,和聚合 api 信息代码几乎相同,聚合了指定 api code
def extract_fn_code(src_api_file_path): # 加载用户提供的 api_list.json api_list_path=os.path.join(src_api_file_path, 'api_list.json') with open(api_list_path, 'r') as f: api_list = json.load(f) # 创建 src/src_api_code.json 存储提取的 api code api_code_path = os.path.join(src_api_file_path, 'src/src_api_code.json') os.makedirs(os.path.dirname(api_code_path), exist_ok=True) # 加载repo中提取的 src_api.json with open(src_api_file_path+"/codebase/api/src_api.json", 'r') as f: src_api_data = json.load(f) # 提取code api_code_dict = {} api_name_list = [] same_api_list = [] api_code = "" api_cnt = 0 for key,value in src_api_data.items(): if key == "src": for src_key,src_value in value.items(): api_file = src_key.split('/')[-1] for key,value in src_value.items(): if key == "fn_def_list": for api in value: api_name = api["fn_meta"]["identifier"] api_code = api["fn_code"] if api_name in api_list: api_cnt += 1 api_code_dict[api_name] = api_code print(api_cnt) with open(api_code_path, 'w', encoding="utf-8") as f: json.dump(api_code_dict, f, indent=2, sort_keys=True, ensure_ascii=False) # Create the 'api_combine' directory if it doesn't exist api_combine_dir = os.path.join(src_api_file_path, 'api_combine') if not os.path.exists(api_combine_dir): os.makedirs(api_combine_dir) # Copy the api_code_path file to the api_combine directory destination_path = os.path.join(api_combine_dir, os.path.basename(api_code_path)) shutil.copy2(api_code_path, destination_path) print(f"Copied {api_code_path} to {destination_path}")
fuzzing
前置

获取当前目录和项目根目录,添加项目根目录到环境变量中

这样可以导入不在当前目录或 site-packages 的模块
执行过程比较长,这里直接拆分,一步一步看。
1、传参处理
args_parser()开始就是传参的设置
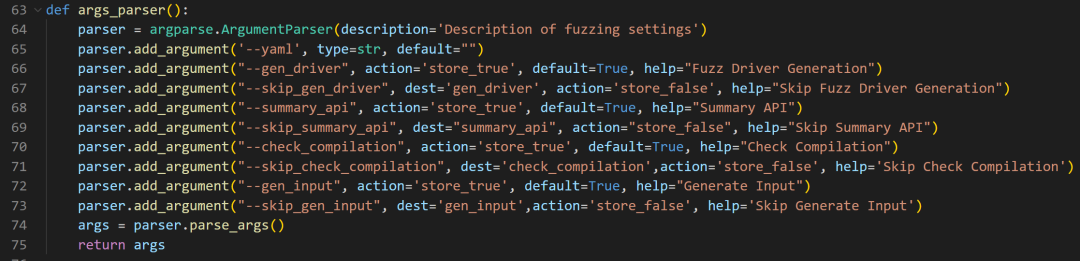
以下是参数的大致介绍
参数名称
类型
默认值
描述
--yaml
字符串
""
指定 YAML 配置文件的路径或内容
--gen_driver
布尔类型
True
是否生成模糊测试驱动
--gen_input
布尔类型
True
是否生成输入
--summary_api
布尔类型
True
是否启用 Summary API
--check_compilation
布尔类型
True
是否检查编译
--skip_check_compilation
布尔类型
False
是否跳过编译检查 (会覆盖--check_compilation)
--skip_gen_driver
布尔类型
False
是否跳过生成模糊测试驱动 (会覆盖--gen_driver)
--skip_gen_input
布尔类型
False
是否跳过生成输入 (会覆盖--gen_input)
--skip_summary_api
布尔类型
False
是否跳过 Summary API (会覆盖--summary_api)
参数处了从用户传入,还有一个从config.yaml文件传入。
需要注意的是:该项目是基于OSS-Fuzz之后有很多包含OSS-Fuzz的基本操作,包括这步的config.yaml也是OSS-Fuzz的基本配置文件。
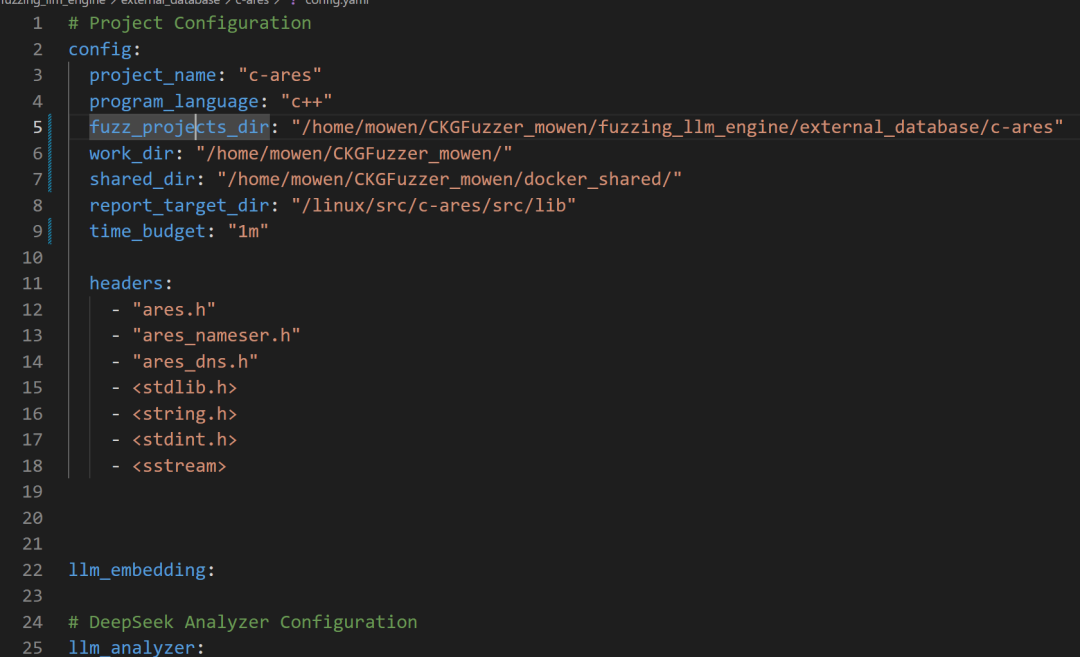
# fuzzing_llm_engine/fuzzing.py # main() # 加载 config if args.yaml is not None and os.path.isfile(args.yaml): with open(os.path.join(args.yaml), 'r') as file: config = yaml.safe_load(file) # 从 config.yaml 中获取项目配置信息 project_config = config['config'] project_name = project_config['project_name'] program_language = project_config['program_language'] fuzz_projects_dir = project_config['fuzz_projects_dir'] work_dir = project_config['work_dir'] shared_dir = project_config['shared_dir'] time_budget = project_config['time_budget'] report_target_dir = project_config['report_target_dir'] # 加载基本文件路径 : 三个聚合文件、agents_result、fuzz_dir( CKGFuzzer_mowen/fuzzing_llm_engine ) api_summary_file = os.path.join(fuzz_projects_dir, "api_summary/api_with_summary.json") api_code_file = os.path.join(fuzz_projects_dir, "src/src_api_code.json") api_call_graph_file = os.path.join(fuzz_projects_dir, "api_combine/combined_call_graph.csv") agents_result_dir = os.path.join(fuzz_projects_dir, "agents_results") fuzz_dir=os.path.join(work_dir,"fuzzing_llm_engine/") # parameters for construting graph knowledge # 构造图参数 chromadb_dir = os.path.join(fuzz_projects_dir, "chromadb/") call_graph_csv = api_call_graph_file all_src_api_file = os.path.join(fuzz_projects_dir, "codebase/api/src_api.json") kg_saved_folder = fuzz_projects_dir exclude_folder_list=[] # 头参数 headers= project_config['headers']
config.yaml
便于之后利用这里放上config.yaml的具体配置
2、获取 Agent
Agent分为两大类就是 :生成文本的语言模型、文本向量化模型。
「1」通过get_model()获取config.yaml配置中的对应的文本语言模型,模型有coder、analyzer两类。
「2」通过get_embedding_model() 获取文本嵌入模型,该模型之后用来进行文本向量化。
「3」设置全局Settings的LLM设置。Settings是来自llama-index里的一个模块,后续的llm就会被内部组件自动调用。
因为模型有coder、analyzer两类,所以在调用时会先行判断需要的版本是否存在,如果不存在则获取另一个版本。
# fuzzing_llm_engine/fuzzing.py # main() # code model for generation and fix ''' 检查配置文件中是否包含 llm_coder 或 llm_analyzer 的配置项。 这两个配置用来调用 LLM 模型,用于生成代码和修复代码。 如果没有找到这两个配置项,则抛出断言错误。 ''' # 生成文本的语言模型 assert "llm_coder" in config or "llm_analyzer" in config, "your config file has to contain at least the llm_coder config or llm_analyzer config" # 获取 llm model coder 版本,如果 config 中没有 llm_coder,则使用 llm_analyzer 的配置。 llm_coder = get_model(config["llm_coder"] if "llm_coder" in config else config["llm_analyzer"]) # code model for combination,summary llm_analyzer = get_model(config["llm_analyzer"] if "llm_analyzer" in config else config["llm_coder"] ) # 文本向量化模型 # 和上面的 llm 逻辑一致 assert "llm_embedding" in config or "llm_code_embedding" in config, "your config file has to contain at least the llm_embedding config or llm_code_embedding config" # common text embedding model llm_embedding= get_embedding_model(config["llm_embedding"] if "llm_embedding" in config else config["llm_code_embedding"] ) # code embedding model llm_embedding_coding = get_embedding_model(config["llm_code_embedding"] if "llm_code_embedding" in config else config["llm_embedding"]) # set default LLM settings # 设置默认 LLM 设置 Settings.llm = get_model(None) #Settings.embed_model = get_embedding_model(None, device='cuda:1') Settings.embed_model = get_embedding_model(None, device='cpu') logger.info(f"Init Default LLM Model and Embedding Model, LLM config: { Settings.llm.metadata } \n Embed config: {Settings.embed_model}")
get_model
「1」默认使用 llama3:70b ,可选择的模型有:deepseek、openai、ollama。
「2」通过OpenAILike、Ollama返回封装了大语言模型服务的客户端类,是对象实例,后续可对该对象直接进行操作
# fuzzing_llm_engine/models/get_model.py def get_model(llm_config=None): # 默认使用 llama3:70b if llm_config is None: return Ollama(model="llama3:70b", base_url="http://csl-server14.dynip.ntu.edu.sg:51030", request_timeout=3600) # http://csl-server14.dynip.ntu.edu.sg:51030" # 三个类型的模型可选 model_name = llm_config['model'] if model_name.startswith("deepseek"): return OpenAILike(model=model_name, api_base=llm_config["base_url"], api_key=llm_config["api_key"], is_chat_model=True, temperature=llm_config["temperature"] ) if model_name.startswith("openai"): model_name = model_name.replace("openai-", "").strip() return OpenAILike(model=model_name, api_base=llm_config["base_url"], api_key=llm_config["api_key"], is_chat_model=True, temperature=llm_config["temperature"]) if model_name.startswith("ollama"): model_name = model_name.replace("ollama-", "").strip() return Ollama(model=model_name, base_url=llm_config["base_url"], request_timeout=llm_config["request_timeout"]) # http://csl-server14.dynip.ntu.edu.sg:51030" assert False, f"Non-support Model Name, The LLM config is {llm_config}. Please use the Ollama Model, OpenAI model and Deepseek Model"
get_embedding_model
「1」默认使用本地部署的BAAI/bge-small-en-v1.5。
「2」调用HuggingFaceEmbedding、OpenAIEmbedding、OllamaEmbedding:返回是对象实例用来语义搜索、RAG 等任务
PS :这里的device是我修改过的,使用cpu进行驱动,原本是使用cuda:1。
# fuzzing_llm_engine/models/get_model.py def get_embedding_model(llm_config=None, device='cpu'): if llm_config is None: # 本地部署的模型 return HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5",device=device) #return OllamaEmbedding( model_name = "llama3:70b", base_url="http://csl-server14.dynip.ntu.edu.sg:51030", ollama_additional_kwargs={"mirostat": 0}) model_name = llm_config['model'] if model_name.startswith("openai"): return OpenAIEmbedding(model=model_name, api_key=llm_config.api_key) if model_name.startswith("ollama"): model_name = model_name.replace("ollama-", "").strip() return OllamaEmbedding( model_name = model_name, base_url=llm_config["base_url"], ollama_additional_kwargs={"mirostat": 0}) assert False, f"Non-support Emb Model Name, The LLM config is {llm_config}. Please use the Ollama Model, OpenAI model and Deepseek Model"
Patch
因为WSL+win10低版本的各种问题,这里我不选择使用 CUDA,需要修改代码使用 CPU 来进行文件向量化。

import torch print(torch.cuda.is_available()) # 如果返回 True,表示可以使用 GPU
3、索引存储
「1」test 文件的索引存储 ,以修复生成的模糊驱动程序
「2」CWE 文件的索引存储

build_test_query
「1」先设置Settings的llm, 后续会隐式调用llm
「2」确定数据和索引目录路径、如果索引已经存在,就加载它。使用StorageContext.from_defaults()创建一个加载上下文;
调用load_index_from_storage()从本地加载已保存的向量索引;
「3」否则,构建新的向量索引。使用SimpleDirectoryReader加载目录下的所有文件(作为文档对象);使用SentenceSplitter把长文档拆成小段(chunk):chunk_size=512:每段最多 512 字符、chunk_overlap=30:相邻段之间有 30 字符重叠。然后调用VectorStoreIndex.from_documents()创建索引:会用Settings.embed_model来将每段文本转为向量;索引构建完成后,用.persist()将构建好的索引持久化到指定目录,方便下次直接加载。
# fuzzing_llm_engine/rag/query_engine_factory.py def build_test_query(database_dir, llm=None, embed_model=None): # 设置 Settings , 后续隐式调用 llm Settings.llm=llm Settings.embed_model=embed_model # 设置测试目录 test_case_index_dir = os.path.join(database_dir, "test_case_index") # 向量索引存储目录 test_dir = os.path.join(database_dir, "test") # 原始测试数据目录,该目录下存放用例以修复生成的模糊驱动程序 # 如果索引已经存在,就加载它 if os.path.exists(test_case_index_dir): logger.info(f"Loading from {test_case_index_dir}") # 加载索引的存储上下文(StorageContext 是 LangChain / LlamaIndex 中用于保存索引的工具) test_case_storage_context = StorageContext.from_defaults(persist_dir=test_case_index_dir) # 从存储中加载索引(可以用于后续向量搜索) test_case_index = load_index_from_storage(test_case_storage_context, show_progress=True) else: logger.info(f"Construct from {test_dir}") # 加载目录下的所有测试用例文档(支持自动读取所有文件) test_case_documents = SimpleDirectoryReader(test_dir, raise_on_error=True).load_data() # 从一组文档中构建向量索引 test_case_index = VectorStoreIndex.from_documents( test_case_documents, # 加载好的文档对象 # 原始文档的处理管道 # SentenceSplitter 是一种文本分段器,会把长文档拆成多个较短的块,便于后续进行嵌入和存储。 # chunk_size=512 每段文本的最大字符数限制为 512。 # chunk_overlap=30 每段之间有 30 个字符的重叠区域 减少上下文断裂的影响 transformations=[SentenceSplitter(chunk_size=512, chunk_overlap=30)], show_progress=True # 显示进度条 ) # 将构建好的索引持久化到指定目录,方便下次直接加载 test_case_index.storage_context.persist(persist_dir=test_case_index_dir) return test_case_index
构建好的效果图如下:

这样就在 test_case_index 下就会生成 test 文件 的存储向量索引
build_cwe_query
和索引存储test文件逻辑一致
# fuzzing_llm_engine/rag/query_engine_factory.py def build_cwe_query(cwe_database_dir, llm=None, embed_model=None): # 和索引存储 test 文件逻辑一致 Settings.llm = llm Settings.embed_model = embed_model cwe_data_dir=os.path.join(cwe_database_dir,"vul_code") cwe_index_dir = os.path.join(cwe_database_dir, "cwe_index") if os.path.exists(cwe_index_dir): logger.info(f"Loading CWE index from {cwe_index_dir}") cwe_storage_context = StorageContext.from_defaults(persist_dir=cwe_index_dir) cwe_index = load_index_from_storage(cwe_storage_context, show_progress=True) else: logger.info(f"Constructing CWE index from {cwe_data_dir}") cwe_documents = SimpleDirectoryReader(cwe_data_dir, raise_on_error=True).load_data() cwe_index = VectorStoreIndex.from_documents( cwe_documents, transformations=[SentenceSplitter(chunk_size=512, chunk_overlap=30)], show_progress=True ) cwe_index.storage_context.persist(persist_dir=cwe_index_dir) return cwe_index
构建好的效果图如下:
cwe 的对应向量索引
4、API 分析(skip)
这步可使用skip_summary_api跳过。
「1」获取API列表 ,初始化每个API的使用次数为0。
「2」创建FuzzingPlanner对象 , 这个对象会负责后续API相关操作。
「3」(args.summary_api) 判断是否需要重新生成API摘要。
├── 是:调用 LLM 分析代码 ➝ summarize_code()
└── 否:直接使用已有摘要文件
两个分支的区别只有,是否调用summarize_code()
「4」将 API 摘要文件复制到api_combine目录、通过extract_api_list提取函数名列表(确保是带摘要信息的),加载完整的 API 源代码文件和 API 摘要文件
这步做的就是给API生成,函数的摘要,对应文件的摘要。
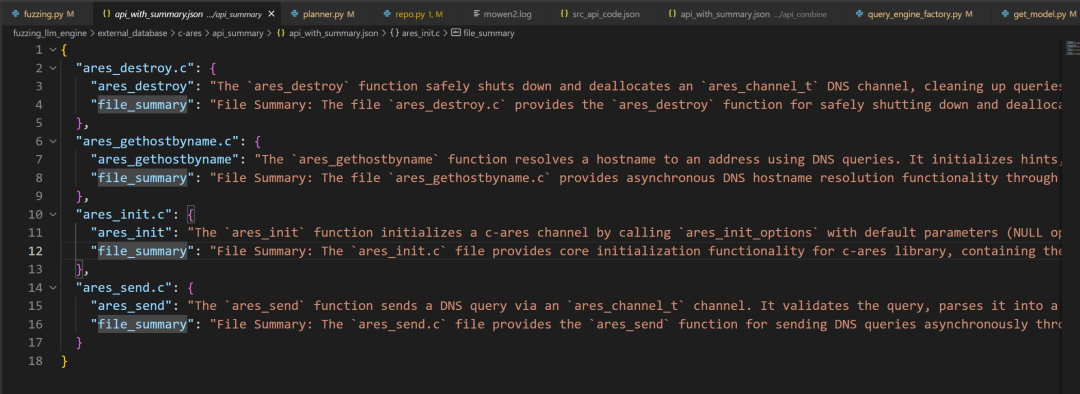
# fuzzing_llm_engine/fuzzing.py # main() # 获取 api_code 的 keys ,即api的函数名 api_list = extract_api_list(api_code_file) # 初始化每个函数的使用次数为 0 api_usage_count = initialize_api_usage_count(api_list) logger.info("Init FuzzingPlanner") plan_agent = planner.FuzzingPlanner( llm = llm_analyzer, llm_embedding = llm_embedding, project_name = project_name, api_info_file = api_summary_file, api_code_file = api_code_file, api_call_graph_file = api_call_graph_file, query_tools = query_tools, api_usage_count = api_usage_count ) if args.summary_api: logger.info("Generate API Summary") # 生成 api 摘要(函数摘要和文件摘要) plan_agent.summarize_code() api_combine_dir = os.path.join(fuzz_projects_dir, "api_combine") os.makedirs(api_combine_dir, exist_ok=True) shutil.copy2(api_summary_file, os.path.join(api_combine_dir, os.path.basename(api_summary_file))) # api_summary/api_with_summary.json copy to api_combine/api_with_summary.json logger.info(f"Copied {api_summary_file} to {api_combine_dir}/{os.path.basename(api_summary_file)}") # 获取函数列表 api_list = plan_agent.extract_api_list() else: logger.info("Skip Generate API Summary") api_combine_dir = os.path.join(fuzz_projects_dir, "api_combine") os.makedirs(api_combine_dir, exist_ok=True) shutil.copy2(api_summary_file, os.path.join(api_combine_dir, os.path.basename(api_summary_file))) logger.info(f"Copied {api_summary_file} to {api_combine_dir}/{os.path.basename(api_summary_file)}") api_list = plan_agent.extract_api_list() src_api_code = json.load(open(api_code_file)) api_summary = json.load(open(api_summary_file))
summarize_code()
「1」载入之前聚合的api.jsoncode.json
「2」遍历每个文件和函数,跳过已经生成过摘要的函数
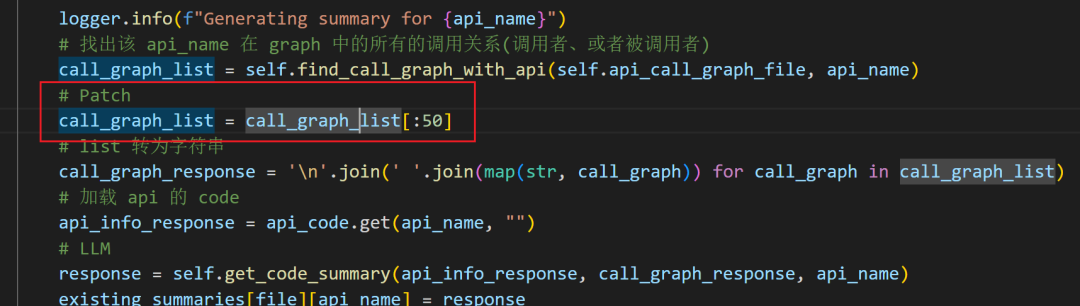
「3」找出该API在graph中的所有的调用关系(调用者、或者被调用者) ,把graph和API code调用get_code_summary让LLM生成函数摘要。
「4」跳过已经存在的文件摘要,把文件下所有函数的摘要合并,调用get_file_summary()让LLM生成一个 "文件整体描述"。
# fuzzing_llm_engine/roles/planner.py def summarize_code(self): logger.debug(f"api_info_file -> {self.api_info_file}") # 载入之前聚合的 api.json code.json with open(self.api_info_file, 'r', encoding='utf-8') as f: existing_summaries = json.load(f) with open(self.api_code_file, 'r', encoding='utf-8') as f: api_code = json.load(f) # 遍历每个文件,为每个 api 生成 summary for file, apis in existing_summaries.items(): # 最初的 api_sum 都为 "" for api_name, api_sum in apis.items(): if api_sum: logger.info(f"Summary for {api_name} already exists. Skipping.") continue logger.info(f"Generating summary for {api_name}") # 找出该 api_name 在 graph 中的所有的调用关系(调用者、或者被调用者) call_graph_list = self.find_call_graph_with_api(self.api_call_graph_file, api_name) call_graph_list = call_graph_list[:50] # list 转为字符串 call_graph_response = '\n'.join(' '.join(map(str, call_graph)) for call_graph in call_graph_list) # 加载 api 的 code api_info_response = api_code.get(api_name, "") # LLM response = self.get_code_summary(api_info_response, call_graph_response, api_name) existing_summaries[file][api_name] = response if not existing_summaries[file].get("file_summary"): api_dict = {file: existing_summaries[file]} file_info_json = json.dumps(api_dict, indent=2) sum_response = self.get_file_summary(file_info_json, file) existing_summaries[file]["file_summary"] = sum_response with open(self.api_info_file, "w", encoding='utf-8') as f: json.dump(existing_summaries, f, indent=2, sort_keys=True, ensure_ascii=False) logger.info(f"API summaries have been updated in {self.api_info_file}")
find_call_graph_with_api
「1」 遍历图数据的每一行,把该API**被调用 **或者调用的关系全部提取出来。
# fuzzing_llm_engine/roles/planner.py def find_call_graph_with_api(self, cg_file_path, api_name): data = pd.read_csv(cg_file_path) # 定义调用图中的列名:调用者和被调用者 column1_name = 'caller' column2_name = 'callee' value_to_find = api_name filtered_data = [] # 遍历调用图数据的每一行,被调用或者被调用全部提取出来 for index, row in data.iterrows(): if row[column1_name] == value_to_find or row[column2_name] == value_to_find: filtered_data.append(row) return filtered_data
get_code_summary
「1」将api code(api_info) 、api graph(call_graph)、api name(api)三个信息套在prompt中,然后调用 LLM 。
# fuzzing_llm_engine/roles/planner.py def get_code_summary(self, api_info, call_graph, api): logger.info("User:") # 格式化提示模板,将 api code(api_info) 、api graph(call_graph)、api name(api) logger.info(self.code_summary_prompt.format(api=api, api_info=api_info, call_graph=call_graph)) code_response = self.llm.complete(self.code_summary_prompt.format(api=api, api_info=api_info, call_graph=call_graph)).text logger.info("Assistant:") logger.info(code_response) return code_response
code_summary_prompt 的提示词,主要是说:这是什么函数名称,API 信息,调用图中的字段。
请根据以上信息,为该函数生成一段不超过 60 个词的代码摘要,内容需覆盖以下两个方面:
1、函数的主要功能。2、函数的使用场景
self.code_summary_prompt = PromptTemplate( "Here is the source code information (function structure, function inputs, function return values) and the function call graph for the function named:\n" "{api}\n" "API information:\n" "{api_info}\n" "Call graph (The call graph is in CSV format, where each column represents the following attributes: 'caller', 'callee', 'caller_src', 'callee_src', 'start_body_start_line', 'start_body_end_line', 'end_body_start_line', 'end_body_end_line', 'caller_signature', 'caller_parameter_string', 'caller_return_type', 'caller_return_type_inferred', 'callee_signature', 'callee_parameter_string', 'callee_return_type', 'callee_return_type_inferred'.):\n" "{call_graph}\n" "Please generate a code summary for this function in no more than 60 words, covering the following two dimensions: code functionality and usage scenario." )
get_fie_summary
「1」将 文件名 和 文件下所有函数的摘要合并信息 (file_info) 套在prompt中,然后调用 LLM 。
# fuzzing_llm_engine/roles/planner.py def get_file_summary(self, file_info, file): logger.info("User:") logger.info(self.file_summary_prompt.format(file_info=file_info, file=file)) file_response = self.llm.complete(self.file_summary_prompt.format(file_info=file_info, file=file)).text logger.info("Assistant:") logger.info(file_response) return file_response
file_summary_prompt提示词
以下是一个 JSON 文件,包含了一个项目文件中的所有 API 信息:
{file}
每个 API 名称后面紧跟着其对应的代码摘要:
{file_info}
请基于每个文件中包含的 API 的代码摘要,为每个文件生成一段不超过 50 个词的文件摘要,内容需涵盖以下两个方面:
1.文件的主要功能;
2.文件的使用场景。
请翻译成以下格式:
File Summary: <你的摘要>
self.file_summary_prompt = PromptTemplate( "Here is a JSON file containing all the API information from a project file:\n" "{file}\n" "with each API name followed by its code summary:\n" "{file_info}\n" "Please generate a file summary for each file in no more than 50 words, based on the code summaries of the APIs contained in each file, considering following two dimensions: file functionality and usage scenario." "Please translate: follow the format below: File Summary: <your summary>" )
Patch
需要清楚的一点是graph 很大,我提供了4个 API,提取出来的graph.csv有120MB ,相当大。行数更是恐怖的28w多行。
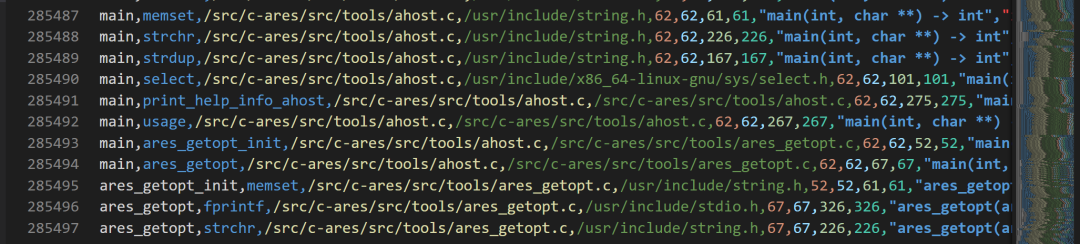
即使只提取相关API的graph 行数也是巨大的,导致发送的tokens巨大,在源代码中是没有做切片处理的,但是deepseek的tokens为6w多 ,测试的时候需要发送某个API的完整graph tokens 都达到了30w多 ,导致报错。

解决方案:
1、做切片处理
2、对内容进行缩减。
3、更换模型
因为只是 API 的描述信息,所以graph 少的情况下,影响不算特别大,所以这里使用对graph 行数进缩减,只发送前50行的调用关系。
5、代码知识图谱(KG)
「1」调用build_kg_query()构建知识图谱,返回值为 4 个语义检索索引,3个图谱索引(这里的file_summary图谱不需要),1 个元数据code_base。
对象名
描述
pg_all_code_index
所有代码的图谱索引
pg_api_summary_index
API 摘要的图谱索引
pg_api_code_index
代码的图谱索引
pg_file_summary_index
摘要文本的图谱索引
summary_text_vector_index
摘要文本的语义向量索引
all_src_code_vector_index
所有源码的语义向量索引
api_src_vector_index
所有 API 源码的向量索引
code_base
元信息
「2」将这4个图谱索引对象转换为BaseRetriever对象,设置similarity_top_k=3表示每次最多返回3个相似结果,为后续对话、查询、代码摘要生成等提供**“上下文信息检索器”**。
「3」创建一个CodeGraphRetriever支持混合多种信息源检索的对象,汇聚代码、摘要、结构等对象,并将CodeGraphRetriever设置到FuzzingPlanner。
◆mode="HYBRID":表示它将同时从多个信息源中选取最合适的检索结果(例如代码 + 摘要的混合搜索);
# fuzzing_llm_engine/fuzzing.py # main() logger.info(f"Init KG Model") #index_pg_all_code, index_pg_api_summary, index_pg_api_code, index_pg_file_summary, summary_api_vector_index, all_src_code_vector_index, api_src_vector_index, code_base # 初始化知识图谱, # 并存储 summary_file_vector_index,api_src_vector_index,summary_api_vector_index,all_src_code_vector_index 图谱索引 pg_all_code_index, pg_api_summary_index, pg_api_code_index, pg_file_summary_index, summary_text_vector_index, all_src_code_vector_index,api_src_vector_index, code_base = \ build_kg_query( chromadb_dir, # 用于存放 chromaDB 向量库的文件夹 call_graph_csv, # API graph 的文件路径 all_src_api_file, # 所有源代码 API 的文件路径 api_summary_file, # API 摘要文件路径 project_name, # 项目名 kg_saved_folder, # 矩量图系列 index 存储路径 initGraphKG = True, # 是否初始化知识图谱 exclude_folder_list=exclude_folder_list, # 要排除的文件夹列表 llm=llm_analyzer, # 用于分析代码的 LLM embed_model=llm_embedding # 文本向量化的 LLM ) # 返回值为 4个语义检索索引,3个图谱索引(这里的file_summary图谱不需要),1一个元数据code_base ''' pg_all_code_index -> 所有代码的索引 pg_api_summary_index -> API 摘要的索引 pg_api_code_index -> 代码的索引 pg_file_summary_index -> 文件摘要的索引 summary_text_vector_index -> 摘要文本的向量索引 all_src_code_vector_index -> 所有源代码的向量索引 api_src_vector_index -> 源代码的向量索引 code_base -> 原始代码 ''' # 将索引对象转换为 BaseRetriever 对象,设置 similarity_top_k=3 表示每次最多返回 3 个相似结果 # 这些 BaseRetriever 是从不同维度(代码、摘要、文件)对输入进行检索,作为提示或上下文的一部分。 pg_index_all_code_retriever = pg_all_code_index.as_retriever(similarity_top_k=3) pg_index_api_summary_retriever = pg_api_summary_index.as_retriever(similarity_top_k=3) pg_index_api_code_retriever = pg_api_code_index.as_retriever(similarity_top_k=3) pg_index_file_summary_retriever = pg_file_summary_index.as_retriever(similarity_top_k=3) # 初始化一个 CodeGraphRetriever,代码检索器 # mode="HYBRID" 使用混合检索方式 code_graph_retriever = CodeGraphRetriever(pg_index_all_code_retriever, pg_index_api_summary_retriever, pg_index_api_code_retriever, pg_index_file_summary_retriever, mode="HYBRID")
# 将 CodeGraphRetriever 设置到 FuzzingPlanner plan_agent.set_code_graph_retriever(code_graph_retriever)
getCodeKG_CodeBase
build_kg_query是getCodeKG_CodeBase的封装,这里直接看getCodeKG_CodeBase()
「1」提取元数据,类型为CodeRepository,通过get_codebase获取代码库信息,包含项目的结构、文件路径、函数定义等内容,并可根据exclude_folder_list排除部分文件夹
「2」加载API摘要,判断是否初始化图谱。
「2.1」初始化图谱:
[2.11]基于graph调用图CSV和源码,构建代码调用图,并生成 5 类“文本节点”用于后续向量化:
◆all_src_text_nodes: 所有源代码的文本节点列表
◆summary_api_nodes: 每个 API 的摘要节点列表
◆file_summary_nodes: 文件摘要的文本节点列表
◆api_src_text_nodes: 每个 API 的源代码文本节点列表
[2.12]对以上节点进行语义向量化(构建Chroma向量库)
[2.13]构建4个属性图索引(Property Graph Index),每个索引代表一个不同视角的图谱,并结合对应的向量数据库,供后续查询使用。
[2.14]持久化图谱索引:调用.persist()将图谱结构和向量嵌入结果写入磁盘,便于下次直接加载。
「2.2」加载图谱,不初始化图谱,区别有:是否调用getCodeCallKGGraph(),配合已存在的vector_store和property_graph_store恢复4个图谱索引对象。
# fuzzing_llm_engine/rag/kg.py def getCodeKG_CodeBase( chromadb_dir: str, \ call_graph_csv:str, src_api_file, api_summary_file,\ project_name, saved_folder, \ llm, embed_model,\ exclude_folder_list, initGraphKG = True, **kwargs): """ Construct the code knowledge graph and code base. Parameters: - chromadb_dir (str): The directory to store the ChromaDB. - call_graph_csv: The path to the call graph CSV file. - src_api_file: The path to the source API file. - api_summary_file: The path to the API summary file. - graph_folder: The folder to store the graph. - project_name: The name of the project. - saved_folder: The folder to save the knowledge graph. - initGraphKG (bool): Whether to initialize the graph knowledge graph. Default is True. This will embed the index ndoes with vectors. - exclude_folder_list (list): List of folders to exclude from the code base. Default is ["c-ares/src/tools"]. - **kwargs: Additional keyword arguments. Returns: - index_pg_all_code: The index of the code property graph. - index_pg_api_summary: The index of the summary property graph. - index_pg_api_code: Then index of the code property graph for API functions - summary_text_vector_index: - all_src_code_vector_index: - code_base: The code base. """ logger.info(f"Constructing code knowledge graph and code base for {project_name}") # CodeRepository 类,获取代码库信息,并排除指定的文件夹 code_base = get_codebase(src_api_file, project_name=project_name, exclude_folder_list=exclude_folder_list) # 加载 API 摘要文件 api_summary = json.load(open(api_summary_file, "r")) # 是否初始化知识图谱 if initGraphKG: # 构建代码调用图和相关节点 # 图存储对象,实体节点列表,所有源代码的文本节点列表,API 摘要的文本节点列表,文件摘要的文本节点列表,API 源代码的文本节点列表 graph_store, entities_nodes, all_src_text_nodes, summary_api_nodes, file_summary_nodes, api_src_text_nodes = \ getCodeCallKGGraph( call_graph_csv, code_base, api_summary, project_name ) # 创建四个 Chroma 向量数据库并获取索引 api_src_vector_index = get_or_construct_chromadb(os.path.join(chromadb_dir, "api_src_text_nodes"), "api_src_text_nodes", api_src_text_nodes, initGraphKG, llm, embed_model) api_src_vector = api_src_vector_index._vector_store all_src_code_vector_index = get_or_construct_chromadb(os.path.join(chromadb_dir, "all_src_text_nodes"), "all_src_text_nodes", all_src_text_nodes, initGraphKG, llm, embed_model) all_src_code_vector = all_src_code_vector_index._vector_store summary_api_vector_index = get_or_construct_chromadb(os.path.join(chromadb_dir, "summary_api_nodes"), "summary_api_nodes", summary_api_nodes, initGraphKG, llm, embed_model) summary_api_vector = summary_api_vector_index._vector_store # file_summary_nodes summary_file_vector_index = get_or_construct_chromadb(os.path.join(chromadb_dir, "file_summary_nodes"), "file_summary_nodes", file_summary_nodes, initGraphKG, llm, embed_model) summary_file_vector = summary_file_vector_index._vector_store # 构建四个相关的属性图索引 # index_pg_all_code = PropertyGraphIndex.from_existing(\ # property_graph_store=graph_store, \ # vector_store=all_src_code_vector, \ # llm=llm, embed_model=embed_model,\ # embed_kg_nodes=True, show_progress=True,use_async=False) # 构建相关的属性图索引 (PropertyGraphIndex) index_pg_all_code = PropertyGraphIndex.from_existing( property_graph_store=graph_store, # 图数据库对象 vector_store=all_src_code_vector, # 向量存储 llm=llm, # 大语言模型 embed_model=embed_model, # 向量嵌入模型 embed_kg_nodes=True, # 对知识图谱中的节点进行嵌入处理 show_progress=True, # 显示构建过程的进度条 use_async=False # 同步执行 ) index_pg_api_code = PropertyGraphIndex.from_existing(\ property_graph_store=graph_store, \ vector_store=api_src_vector, \ llm=llm, embed_model=embed_model,\ embed_kg_nodes=True, show_progress=True,use_async=False) index_pg_api_summary = PropertyGraphIndex.from_existing(\ property_graph_store=graph_store, \ vector_store=summary_api_vector,\ llm=llm, embed_model=embed_model,\ embed_kg_nodes=True, show_progress=True,use_async=False) index_pg_file_summary = PropertyGraphIndex.from_existing(\ property_graph_store=graph_store, \ vector_store=summary_file_vector,\ llm=llm, embed_model=embed_model,\ embed_kg_nodes=True, show_progress=True,use_async=False) # 存储图谱索引 # 这一步会保存嵌入后的向量数据、图谱信息等到磁盘,供后续加载使用 saved_pg_api_code_dir = os.path.join(saved_folder, "kg", "index_pg_api_code") saved_pg_all_code_dir = os.path.join(saved_folder, "kg", "index_pg_all_code") saved_pg_api_summary_dir = os.path.join(saved_folder, "kg", "index_pg_api_summary") saved_pg_file_summary_dir = os.path.join(saved_folder, "kg", "index_pg_file_summary") os.makedirs(saved_pg_all_code_dir, exist_ok=True) os.makedirs(saved_pg_api_summary_dir, exist_ok=True) os.makedirs(saved_pg_api_code_dir, exist_ok=True) os.makedirs(saved_pg_file_summary_dir, exist_ok=True) index_pg_all_code.storage_context.persist(persist_dir=saved_pg_all_code_dir) index_pg_api_summary.storage_context.persist(persist_dir=saved_pg_api_summary_dir) index_pg_api_code.storage_context.persist(persist_dir=saved_pg_api_code_dir) index_pg_file_summary.storage_context.persist(persist_dir=saved_pg_file_summary_dir) else: # 加载4个图谱索引 saved_pg_all_code_dir = os.path.join(saved_folder, "kg", "index_pg_all_code") saved_pg_api_summary_dir = os.path.join(saved_folder, "kg", "index_pg_api_summary") saved_pg_api_code_dir = os.path.join(saved_folder, "kg", "index_pg_api_code") saved_pg_file_summary_dir = os.path.join(saved_folder, "kg", "index_pg_file_summary") all_src_code_vector_index = get_or_construct_chromadb(os.path.join(chromadb_dir, "all_src_text_nodes"), "all_src_text_nodes", all_src_text_nodes, initGraphKG, llm, embed_model) summary_api_vector_index = get_or_construct_chromadb(os.path.join(chromadb_dir, "summary_api_nodes"), "summary_api_nodes", summary_api_nodes, initGraphKG, llm, embed_model) api_src_vector_index = get_or_construct_chromadb(os.path.join(chromadb_dir, "api_src_text_nodes"), "api_src_text_nodes", api_src_text_nodes, initGraphKG, llm, embed_model) summary_file_vector_index = get_or_construct_chromadb(os.path.join(chromadb_dir, "file_summary_nodes"), "file_summary_nodes", file_summary_nodes, initGraphKG, llm, embed_model) index_pg_all_code = PropertyGraphIndex.from_existing(\ property_graph_store = SimplePropertyGraphStore.from_persist_dir(saved_pg_all_code_dir), \ vector_store=all_src_code_vector_index._vector_store, \ embed_kg_nodes=True, show_progress=True, \ llm=llm, embed_model=embed_model, **kwargs) index_pg_api_summary = PropertyGraphIndex.from_existing(\ property_graph_store = SimplePropertyGraphStore.from_persist_dir(saved_pg_api_summary_dir), \ vector_store=summary_api_vector_index._vector_store,\ embed_kg_nodes=True, show_progress=True, \ llm=llm, embed_model=embed_model, **kwargs) index_pg_api_code = PropertyGraphIndex.from_existing(\ property_graph_store = SimplePropertyGraphStore.from_persist_dir(saved_pg_api_summary_dir), \ vector_store=api_src_vector_index._vector_store,\ embed_kg_nodes=True, show_progress=True, \ llm=llm, embed_model=embed_model, **kwargs) index_pg_file_summary = PropertyGraphIndex.from_existing(\ property_graph_store = SimplePropertyGraphStore.from_persist_dir(saved_pg_file_summary_dir), \ vector_store=summary_file_vector_index._vector_store,\ embed_kg_nodes=True, show_progress=True, \ llm=llm, embed_model=embed_model, **kwargs) return index_pg_all_code, index_pg_api_summary, index_pg_api_code, index_pg_file_summary, summary_api_vector_index, all_src_code_vector_index, api_src_vector_index, code_base
get_codebase
get_codebase主要就是CodeRepository.construct_nodes_fn_doc的封装。
def get_codebase(src_api_file, project_name="c-ares", exclude_folder_list=["c-ares/src/tools"]) -> CodeRepository: method_code = json.load(open(src_api_file, "r")) pkg = CodeRepository(project_name) file_id_dict, (struct_def, typdef_struct_alias), (enum_def, typdef_enum_alias), fn_def = pkg.construct_nodes_fn_doc(method_code, exclude_folders=exclude_folder_list) pkg.file_id_mapping = file_id_dict pkg.struct_def = struct_def pkg.typdef_struct_alias = typdef_struct_alias pkg.enum_def = enum_def pkg.typdef_enum_alias = typdef_enum_alias pkg.fn_def = fn_def pkg.graphs = [] #graphs return pkg
construct_nodes_fn_doc
从 API 数据(源码和头文件)中提取结构化的节点信息,包括文件、函数、结构体、枚举等,为后续构建图谱提供语义实体。
「1」获取源文件和头文件信息,获取项目路径前缀(这里是我Patch的部分,因为当路径为绝对地址,按照源代码的相对地址就会替换失败,导致后面全部提取失败,提取前缀增加兼容性。后续前缀会被替换为空,然后再将数据集合。)
「2」遍历所有源文件和头文件,并读取文件内容(读取的时候做了编码兼容),使用replace()替换前缀(PS:这点很重要影响后续整个流程),构建文件节点字典file_id_dict。
「3」调用process_source_files()提取源代码中的函数定义、全局变量、结构体、枚举节点 (src_fn_def_list_list, src_global_var_node_list, src_struct_node_list, src_enum_node_list)。
「4」构建结构体、枚举定义与别名映射,最终两个字典形如:struct_def: struct 名字 -> struct 定义节点,typdef_struct_alias: struct typedef别名 -> 原始 struct 名。
「5」构建函数定义映射fn_dec,每个函数以 “文件路径-函数名” 为键,保存其定义信息。
# 构建代码图中的各种节点信息(函数、结构体、枚举、文件等)。 def construct_nodes_fn_doc(self, api_data, exclude_folders = []): ''' 构建代码图中的各种节点信息(函数、结构体、枚举、文件等)。 节点ID的格式: - project_name/file_path-method_name-param_name - project_name/file_path-struct_name-param_name - project_name/file_path-method_name-statement_id 参数: - api_data: 包含源代码和头文件信息的字典,格式: { "src": {文件路径: 函数定义}, "head": {头文件路径: 函数定义} } - exclude_folders: 排除分析的文件夹列表 返回: - file_id_dict: 文件节点的元数据字典 - (struct_def, typdef_struct_alias): 结构体定义和typedef结构体别名映射 - (enum_def, typdef_enum_alias): 枚举定义和typedef枚举别名映射 - fn_dec: 函数定义信息字典 ''' source_code = api_data["src"] header_code = api_data["head"] api_path = list(source_code.keys())[0] api_path_prefix_len = api_path.find(f"{self.project_name}") + len(f"{self.project_name}") api_path_prefix = api_path[:api_path_prefix_len] file_id_dict = {} # 遍历 project/codebase/api/src_api.json 中所有 keys -> 构造文件节点的元数据字典 file_id_dict for idx, all_files in enumerate([list(source_code.keys()), list(header_code.keys()) ]): for fname in all_files: logger.info(f"Processing file: {fname}") # 读取文件内容,做了编码处理 try: with open(fix_file_path(fname), "r", encoding='utf-8') as f: file_code = f.read() except UnicodeDecodeError: with open(fix_file_path(fname), "rb") as f: raw_data = f.read() detected_encoding = chardet.detect(raw_data)['encoding'] logger.info(f"Detected encoding for {fname}: {detected_encoding}") try: file_code = raw_data.decode(detected_encoding) except: logger.error(f"Failed to decode {fname} with detected encoding {detected_encoding}. Skipping this file.") continue # Patch #fid = fname.replace(f"../docker_shared/source_code/{self.project_name}", "") fid = fname.replace(api_path_prefix, "") # 构建该文件的节点元数据 metadata_file_node = { "id":fid, "file_name":os.path.basename(fname), "file_path":fid, "project":self.project_name, "code":file_code} file_id_dict[fid] = metadata_file_node # 提取源代码中的函数定义、全局变量、结构体、枚举节点 src_fn_def_list_list, src_global_var_node_list, src_struct_node_list, src_enum_node_list = self.process_source_files(source_code, exclude_folders) head_fn_def_list_list, head_global_var_node_list, head_struct_node_list, head_enum_node_list = self.process_source_files(header_code, exclude_folders) ### 构建结构体定义与 typedef 映射 ### struct_def = {} # struct 名字 -> struct 定义节点 typdef_struct_alias = {} # struct typedef别名 -> 原始 struct 名 # struct_declar = {} for struct in head_struct_node_list + src_struct_node_list: if len(struct['name'].strip()) != 0 and len(struct['parameters']) != 0: struct_def[struct['name']] = struct # 有名且有字段的定义 else: # 处理 typedef struct 形式 if struct["code"].startswith("typedef"): alias_name, name = struct["code"].split()[-1], struct["code"].split()[-2] typdef_struct_alias[alias_name] = name # 与 struct 逻辑一致 enum_def = {} typdef_enum_alias = {} # enum_declar = {} for enum in head_enum_node_list + src_enum_node_list: if len(enum['name'].strip()) != 0 and len(enum['parameters']) != 0: enum_def[enum['name']] = enum else: if enum["code"].startswith("typedef"): alias_name, name = enum["code"].split()[-1], enum["code"].split()[-2] typdef_enum_alias[alias_name] = name fn_dec = {} for fdef in src_fn_def_list_list + head_fn_def_list_list: fn_dec[ f"{fdef['fid']}-{fdef['name']}"] = fdef # 文件id-函数名 -> 函数定义 return file_id_dict, (struct_def, typdef_struct_alias), (enum_def, typdef_enum_alias), fn_dec
process_source_files
从预处理后的代码结构信息中提取并标准化出“节点”数据(函数、结构体、枚举、全局变量),为后续图谱建模准备实体数据。
「1」提取项目路径前缀(这里是我Patch的部分,因为当路径为绝对地址,按照源代码的相对地址就会替换失败,导致后面全部提取失败,提取前缀增加兼容性。后续前缀会被替换为空,然后再将数据集合。)
「2」遍历所有文件解析每个文件的节点,并跳过指定排除的文件夹
「3」构建函数、结构体、枚举、全局变量4 个节点信息(重点),标准化成{fid}-{函数名}的唯一 ID,附带代码和参数信息。
# fuzzing_llm_engine/rag/code_base.py def process_source_files(self, code_data, exclude_folders): fn_def_list_node_list = [ ] global_var_node_list = [] struct_node_list = [] enum_node_list = [] # Patch api_path = list(code_data.keys())[0] api_path_prefix_len = api_path.find(f"{self.project_name}") + len(f"{self.project_name}") api_path_prefix = api_path[:api_path_prefix_len] logger.debug(f"{api_path_prefix}") for fname in code_data: values = code_data[fname] fn_def_list = values["fn_def_list"] # List of function definitions, Method Nodoes struct_list = values["struct_node_list"] # List of struct definitions, Struct Nodes include_list = values["include_list"] # include relationship between file and method global_varibales = values["global_variables"] # fn_declaraion = values["fn_declaraion"] enum_declaration = values["enumerate_node_list"] # remmove the shared folder name # Patch # fid = fname.replace(f"../docker_shared/source_code/{self.project_name}", "") fid = fname.replace(api_path_prefix, "") if os.path.dirname(fid) in exclude_folders: continue for i, fdef in enumerate(fn_def_list): fn_code = fdef['fn_code'].strip() fn_meta = fdef['fn_meta'] fn_name = fn_meta['identifier'] parameters = fn_meta['parameters'] meta_node_info = {"id":f"{fid}-{fn_name}", "fid":fid, "project": self.project_name, "code":fn_code, "name":fn_name, "parameters": parameters} fn_def_list_node_list.append(meta_node_info) for gi, gv in enumerate(global_varibales): meta_gnode_info = {id:f"{fid}-g-{gi}", "code":gv, "name":gi, "project": self.project_name, "fid":fid} global_var_node_list.append(meta_gnode_info) for s in struct_list: struct_body = s[0] struct_parameters = s[1] struc_name = s[2] struct_id = f"{fid}-{struc_name}" meta_struct_node_info = {"id":struct_id, "name":struc_name, "fid":fid,"parameters":struct_parameters, "code":struct_body} struct_node_list.append(meta_struct_node_info) # 添加 enum for e in enum_declaration: enum_body = e[0] enum_parameters = e[1] enum_name = e[2] enum_id = f"{fid}-{enum_name}" meta_enum_node_info = {"id":enum_id, "name":enum_name, "fid":fid, "parameters":enum_parameters, "code":enum_body} enum_node_list.append(meta_enum_node_info) return fn_def_list_node_list, global_var_node_list, struct_node_list, enum_node_list
在construct_nodes_fn_doc函数中,使用replace来替换,这样其实可以抵消项目中有特殊符号导致的问题,但是当使用项目为c-ares时,我们的路径又是绝对地址这样就会替换失败,导致后面全部提取失败。
Patch
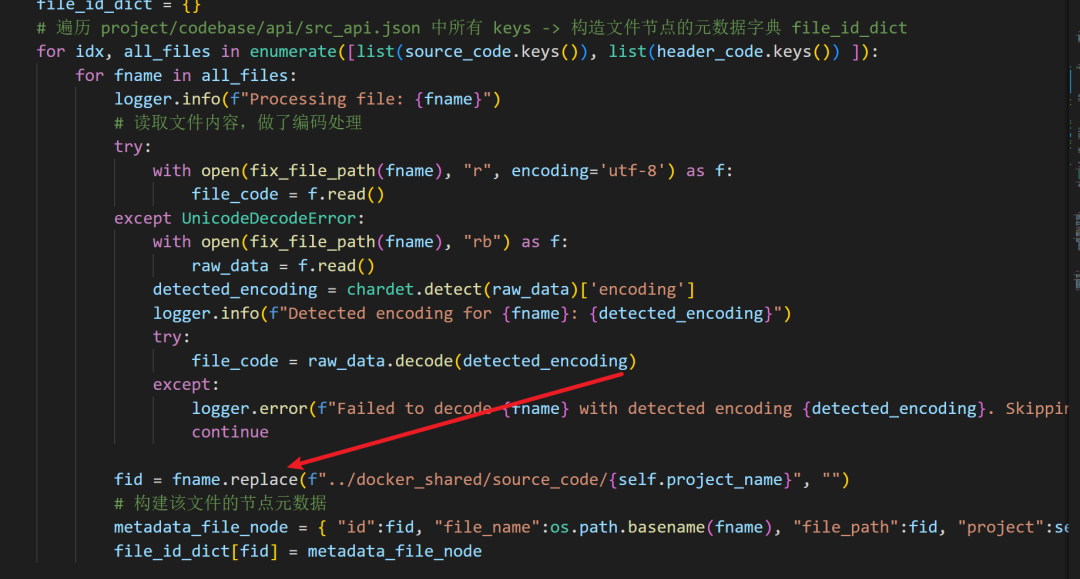
上面代码在fuzzing_llm_engine/rag/kg.py中的get_codebase()被调用,原目的是替换路径用来构建源数据为图存储对象。
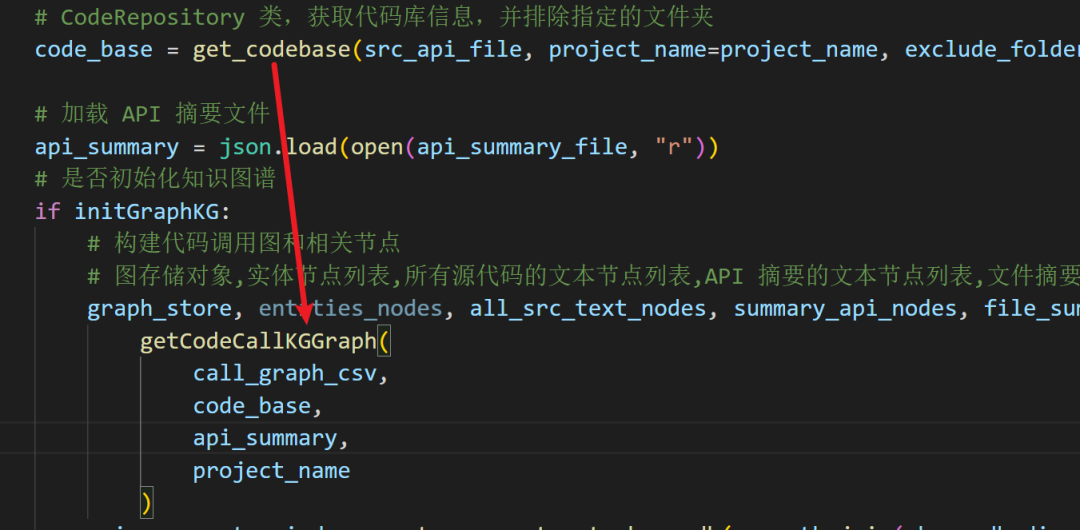
但在后面的getCodeCallKGGraph()中调用,使用 "-" 来分割文件名和文件函数,这里就有问题了,当路径为绝对地址不能被replace()时,就会导致全部提取失败。
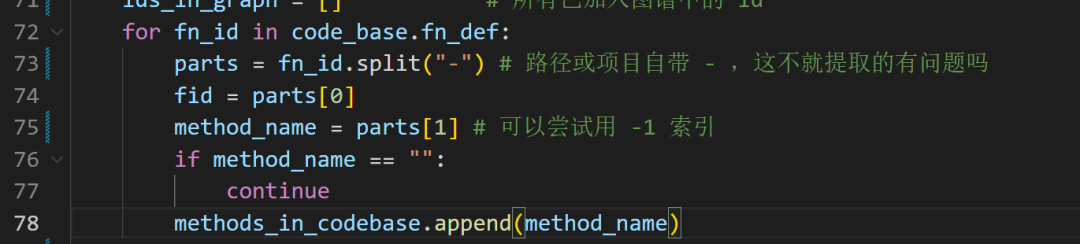
解决方案:
1、替换 “-”,用其他更特殊的符号如 "$" 来区别
2、使用相对路径进行api的提取
3、修改 replace 函数代码
这里使用第三种方案,添加前缀获取并替换模式
在construct_nodes_fn_doc()函数中修改以下代码
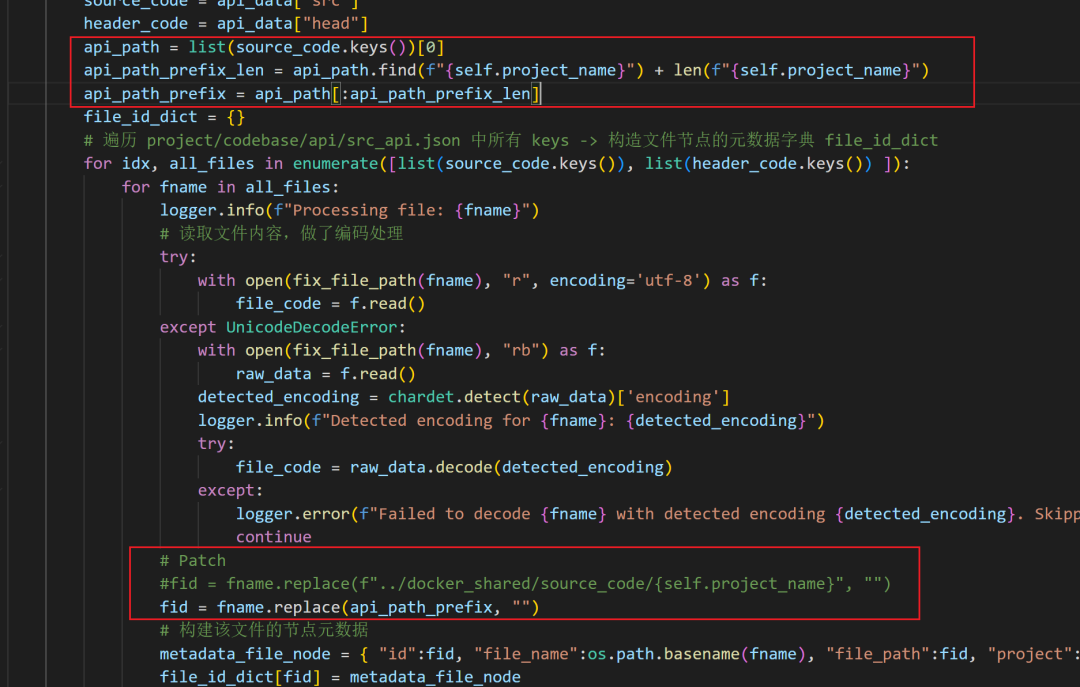
在该函数中还会调用process_source_files()里面也使用了类似逻辑。
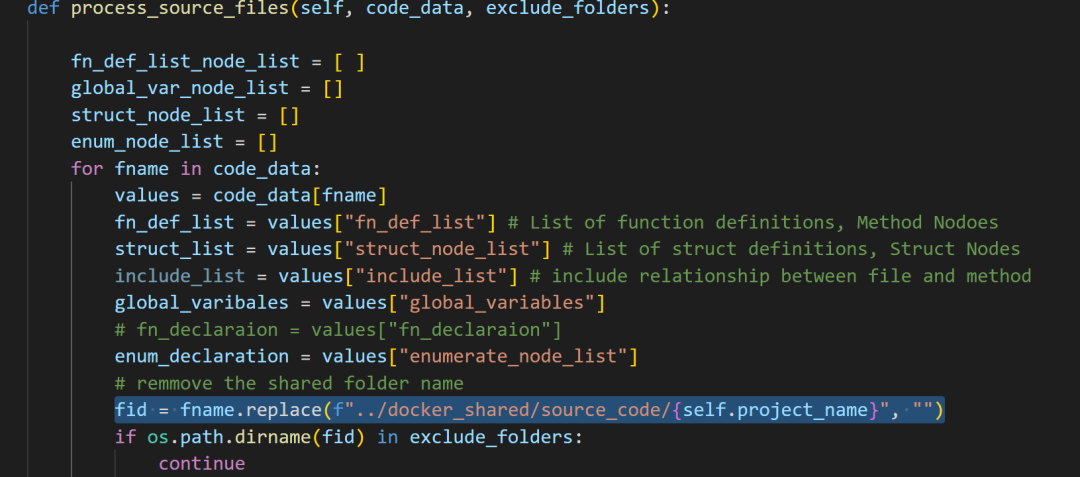
修改如下:
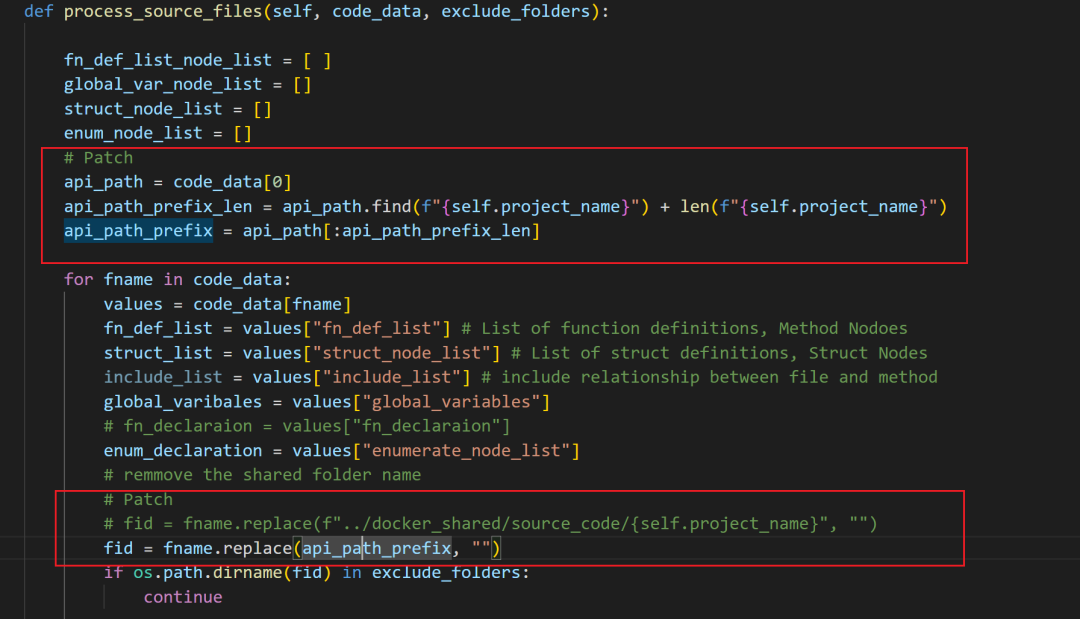
修改效果,这样修改之后就能规避项目或者路径中自带的-干扰。
get_or_construct_chromadb
「1」创建一个持久化的 Chroma 客户端(连接到磁盘上的数据)
「2」获取或创建指定名称的 collection(类似于数据库中的表)。
「3」用collection构建ChromaVectorStore, 封装collection,变成llama-index中支持的向量存储接口。
「4.1」初始化新的向量索引 :
设置 LLM 和嵌入模型、创建向量存储上下文、构建向量索引并写入TextNodes。
「4.2」不初始化新的向量索引,从现有向量数据库加载索引。
根据函数调用关系和代码信息,构建一个用于图查询(Knowledge Graph Query)的知识图谱,其中包括函数、文件、调用关系、函数摘要、源代码等多种信息,最终返回构建好的图谱及其相关节点集合。
「1」使用 pandas 读取 call_graph_csv 文件、初始化图存储对象。
「2」初始化实体节点、关系和源代码块的列表,维护methods_in_codebase(所有项目中定义的方法名)-> 遍历所有函数定义提取函数名。
「3」逐行构建调用图中的实体节点和边,对每一条调用记录:
◆判断 caller 和 callee 是否为项目中的函数(否则视为库函数)
◆提取函数签名、源代码(如果有)
◆判断是否有 API 摘要信息并加入属性
◆为函数和文件创建实体节点 (EntityNode)
◆为调用关系创建边 (Relation):CALLS:函数调用、CONTAIN:文件包含函数。
「4」插入节点和边到图谱
getCodeCallKGGraph

「5」构建函数定义和摘要的文本节点 (TextNode),遍历所有函数定义fn_def:
如果该函数已添加到图谱中,则构建对应的TextNode(纯文本节点)
◆all_src_text_nodes:所有函数代码节点
◆summary_api_nodes: 函数级摘要节点
◆file_summary_nodes:文件级摘要节点
◆API_src_text_nodes:摘要中提到的 API 函数的源码节点
# fuzzing_llm_engine/rag/kg.py def getCodeCallKGGraph(method_call_csv_file:str, code_base:CodeRepository, api_summary:dict,project_name:str): """ 构建用于图查询的节点。 参数: method_call_csv_file (str): 方法调用关系的 CSV 文件路径。 code_base (CodeRepository): 提供代码信息的对象。 api_summary (dict): API 摘要信息。 project_name (str): 项目名称。 返回: graph_store (SimplePropertyGraphStore): 图存储对象。 entities (list): 实体节点列表。 all_src_text_nodes (list): 所有源代码的文本节点列表。 summary_api_nodes (list): API 摘要的文本节点列表。 file_summary_nodes (list): 文件摘要的文本节点列表。 API_src_text_nodes (list): API 源代码的文本节点列表。 """ # 初始化图存储对象 graph_store = SimplePropertyGraphStore() # Step 1: Read the CSV file with pandas # Step 1: 使用 pandas 读取 call_graph_csv 文件 df = pd.read_csv(method_call_csv_file) # Step 2: 初始化实体节点、关系和源代码块的列表 # Step 2: Init Text Node with the specific id. The id has to be the same with EntityNode (name is id) entities = [] # 所有实体节点列表 relations = [] # 所有关系边列表 methods_in_codebase = [ ] # 所有项目中定义的方法名 all_src_text_nodes = [ ] # 所有函数定义对应的文本节点 API_src_text_nodes = [ ] # 所有 API 摘要关联函数的源代码节点 summary_api_nodes = [ ] # API 摘要的文本节点 file_summary_nodes = [ ] # 文件级别的摘要文本节点 ids_in_graph = [] # 所有已加入图谱中的 id # 维护 methods_in_codebase 遍历所有函数定义提取函数名 for fn_id in code_base.fn_def: parts = fn_id.split("-") # 路径或项目自带 - ,这不就提取的有问题吗 fid = parts[0] method_name = parts[1] # 可以尝试用 -1 索引,但是 fid 仍然有问题 if method_name == "": continue methods_in_codebase.append(method_name) # Step 3: 初始化实体、关系和源代码块的列表 # Step 3: Initialize lists for entities, relations, and source chunks # 遍历 call_graph_csv 中每一行记录,构建调用关系图 for _, row in df.iterrows(): caller = row['caller'] # 调用方函数名 callee = row['callee'] # 被调用方函数名 # if caller == "ares__buf_append" or callee=="ares__buf_append": # print("debug") caller_src_code = "" # 调用方法的源代码(默认空) callee_src_code = "" # 被调用方法的源代码(默认空) relationship_call = "CALLS" # 默认关系为调用 CALLS caller_src = row['caller_src'] # 调用方法的文件路径 callee_src = row['callee_src'] # 被调用方法的文件路径 # 跳过缺失源码路径的记录 pd.isna -> 检测缺失值的方法 if pd.isna(caller_src) or pd.isna(callee_src): continue callee_src = callee_src.replace(f"/src/{project_name}", "") caller_src = caller_src.replace(f"/src/{project_name}", "") # 获取函数签名 caller_signature = row['caller_signature'] callee_signature = row['callee_signature'] # Step check if the method is in code or from standard or third library # 判断调用方法是否是项目内部方法,如果是则提取 函数代码 if caller in methods_in_codebase: caller_label = "METHOD" caller_src_id = f"{caller_src}-{caller}" if caller_src_id in code_base.fn_def: caller_src_code = code_base.fn_def[caller_src_id]['code'] else: caller_label = "LIBRARY_METHOD" relationship_call = "LIBRARY_CALLS" if callee in methods_in_codebase: callee_label = "METHOD" callee_src_id = f"{callee_src}-{callee}" if callee_src_id in code_base.fn_def: callee_src_code = code_base.fn_def[callee_src_id]['code'] else: callee_label = "LIBRARY_METHOD" relationship_call = "LIBRARY_CALLS" # Step 4: 创建调用者和被调用者的实体节点,添加调用者函数节点 # Step 4: Create entities for the caller and callee # add entity caller funciton node if caller_src_code.strip(): caller_properties = {"signature": caller_signature, "file": caller_src, "source code": f"```code\n{caller_src_code}\n```"} else: caller_properties = {"signature": caller_signature, "file": caller_src} # 如有摘要则加入摘要属性 caller_summary = check_funciton_has_summary(caller_src, caller, api_summary) if len(caller_summary): caller_properties['summary'] = caller_summary # 构建 caller 的 EntityNode caller_entity = EntityNode( name=f"{caller_src}-{caller}", label=caller_label, properties=caller_properties ) # 函数的实体节点 加入图谱的 id 形式为 <caller_src>-<caller> (<相对文件路径>-<函数名>) ids_in_graph.append(f"{caller_src}-{caller}") # check if file summary in api_summary # 若文件有摘要,则构造文件级实体节点 file_name = os.path.basename(caller_src) if file_name in api_summary: file_summary = api_summary[file_name]["file_summary"] file_proerties = {"file summary":file_summary} else: file_proerties = {} # 构建文件的 EntityNode caller_file_entity = EntityNode( name=f"{caller_src}", label="File", properties=file_proerties ) # 源文件节点 加入图谱的 id 形式为 <caller_src>(文件路径) ids_in_graph.append(f"{caller_src}") # add entity calee funciton node # 构造 callee 的属性 ,与 caller 逻辑一致 if callee_src_code.strip(): callee_properties = {"signature": callee_signature, "file": callee_src, "source code": f"```code\n{callee_src_code}\n```"} else: callee_properties = {"signature": callee_signature, "file": callee_src} callee_summary = check_funciton_has_summary(callee_src, callee, api_summary) if len(callee_summary): callee_properties['summary'] = callee_summary callee_entity = EntityNode( name=f"{callee_src}-{callee}", label=callee_label, properties=callee_properties ) # check if file summary in api_summary file_name = os.path.basename(callee_src) if file_name in api_summary: file_summary = api_summary[file_name]["file_summary"] file_proerties = {"summary":file_summary} ids_in_graph.append(f"{callee_src}-{callee}") callee_file_entity = EntityNode( name=f"{callee_src}", label="File", properties=file_proerties ) ids_in_graph.append(f"{callee_src}") # 汇总到 entities ,所有实体节点列表 entities.extend([caller_entity, callee_entity,caller_file_entity, callee_file_entity]) # Step 5: 创建调用者和被调用者之间的关系(使用边来表示) # Step 5: Create a relation between caller and callee # 边类 Relation ,一个函数边(调用),两个文件边(包含) relation = Relation( label=relationship_call, # label(关系类型): "CALLS" 或 "CONTAIN" source_id=caller_entity.id, # 起点节点的 ID target_id=callee_entity.id, # 终点节点的 ID properties={} # 关系的附加属性 ) file_relation1 = Relation( label="CONTAIN", source_id=caller_file_entity.id, target_id=caller_entity.id, properties={} ) file_relation2 = Relation( label="CONTAIN", source_id=callee_file_entity.id, target_id=callee_entity.id, properties={} ) relations.append(relation) relations.append(file_relation1) relations.append(file_relation2) # Step 6: 将实体、关系和文本节点插入到图存储中 # Step 5: Upsert entities, relations, and text nodes into the graph store graph_store.upsert_nodes(entities) # node 插入图 graph_store.upsert_relations(relations) # relation 插入图 # graph_store.upsert_llama_nodes(source_chunks) index_ids = [] # 用来存储节点的 ID,用于索引和去重。 unique_index_ids = [] # 用来存储唯一的节点 ID,避免重复。 file_id = [] # 用来存储文件的 ID,用来确保每个文件的总结信息仅插入一次。 for fn_id in code_base.fn_def: parts = fn_id.split("-") fid = parts[0] method_name = parts[1] if method_name == "": continue # if method_name == "ares__buf_append": # print(k) # print(code_base.fn_def[k]) # print("dbug") # 获取 code if code_base.fn_def[fn_id]["code"].strip(): src_node = TextNode( id_= fn_id, text=code_base.fn_def[fn_id]["code"].strip() ) # 如果该函数的 ID 已经存在于图中 # 且该文本节点还没有被添加到 all_src_text_nodes(所有函数定义对应的文本节点) 中,则添加。 if fn_id in ids_in_graph and src_node not in all_src_text_nodes: all_src_text_nodes.append(src_node) index_ids.append(fn_id) # 获取文件名 file_name = os.path.basename(fid) # 如果文件名存在于 project/api_summary/api_with_summary.json 中 if file_name in api_summary: for fn_name in api_summary[file_name]: if fn_name == "file_summary": sum_node = TextNode( id_= fid, text=api_summary[file_name][fn_name] ) if sum_node.id_ in ids_in_graph and sum_node.id_ not in file_id: file_summary_nodes.append(sum_node) file_id.append(sum_node.id_) else: sum_node = TextNode( id_= f"{fid}-{fn_name}", text=api_summary[file_name][fn_name] ) if sum_node.id_ in ids_in_graph and sum_node not in summary_api_nodes: summary_api_nodes.append(sum_node) index_ids.append(sum_node.id_) for fn_name in api_summary[file_name]: if fn_name == "file_summary": continue if f"{fid}-{fn_name}" in code_base.fn_def: api_src_code_node = TextNode( id_= f"{fid}-{fn_name}", text=code_base.fn_def[f"{fid}-{fn_name}"]["code"].strip() ) # assert api_src_code_node.id_ not in unique_index_ids unique_index_ids.append(api_src_code_node.id_) # else: # print(f"Debug {fid}-{fn_name}") if api_src_code_node.id_ in ids_in_graph and api_src_code_node not in API_src_text_nodes: API_src_text_nodes.append(api_src_code_node) # json.dump(ids_in_graph, open("ids_in_graph.json", "w"), indent=2) # json.dump(index_ids, open("index_ids.json", "w"), indent=2) # json.dump(unique_index_ids, open("unique_index_ids.json", "w"), indent=2) # logger.info(f"Number of API_src_text_nodes: {len(API_src_text_nodes)}") # logger.info(f"Number of len API_src_text_nodes: {len(list(set([n.id_ for n in API_src_text_nodes])))}") return graph_store, entities, all_src_text_nodes, summary_api_nodes, file_summary_nodes, API_src_text_nodes
因为这块核心区域代码量相对来比较庞大,阅读起来理解起来相对比较复杂,但是他主要就做了如下几件事:
1、主要目的是为了: 获取图谱并持久化图谱索引
2、为了获取图谱就需要获取 **文本节点 **和关系图,所以要先调用getCodeCallKGGraph()获取。
3、获取文本节点,就需要代码库信息(项目的结构、文件路径、函数定义等内容),所以要先调用get_codebase()获取。
4、文本节点就是各种字典的集合,关系图分为 节点、边两个关系。
5、加载4个图谱索引,需要关系图和文本节点,所以会在获取 文本节点、关系图 后都存储起来。
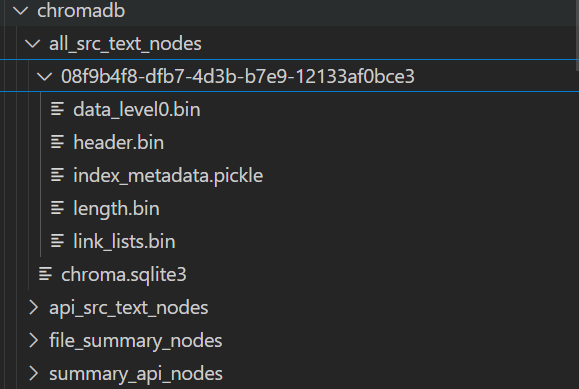
在保存之后kg目录下会出现4个文件夹:
◆所有源代码的文本节点列表
◆API 摘要的文本节点列表
◆文件摘要的文本节点列表
◆API 源代码的文本节点列表
代码知识图谱(KG)小结:
对应四个Chroma向量数据库
6、初始化各种 Agent
「1」gen_agent -> 初始化 FuzzingGenerationAgent,用于生成模糊测试驱动程序
「2」fix_agent -> 初始化 CompilationFixAgent,用于修复编译错误
「3」input_agent -> 初始化 InputGenerationAgent,用于生成模糊测试输入
「4」crash_analyze_agent -> 初始化 CrashAnalyzer,用于分析崩溃信息
logger.info("Init FuzzingGenerationAgent") # 初始化 FuzzingGenerationAgent,用于生成模糊测试驱动程序 gen_agent = fuzz_generator.FuzzingGenerationAgent( llm_coder = llm_coder, llm_analyzer = llm_analyzer, llm_embedding = llm_embedding, database_dir = fuzz_projects_dir, headers = headers, query_tools = query_tools, language = program_language ) logger.info(f"Init CompilationFixAgent") test_case_index_dir = os.path.join(fuzz_projects_dir, "test_case_index/") # 初始化 CompilationFixAgent,用于修复编译错误 fix_agent = compilation_fix_agent.CompilationFixAgent( llm_coder=llm_coder, llm_analyzer=llm_analyzer, llm_embedding=llm_embedding, query_tools=query_tools, max_fix_itrs=5 ) logger.info(f"Init InputGenerationAgent") input_dir = os.path.join(work_dir, f"docker_shared/fuzz_driver/{project_name}/syntax_pass_rag/" ) output_dir = os.path.join(work_dir, f"fuzzing_llm_engine/build/work/{project_name}/" ) # 初始化 InputGenerationAgent,用于生成模糊测试输入 input_agent = input_gen_agent.InputGenerationAgent( input_dir = input_dir, output_dir = output_dir, llm = llm_analyzer, llm_embedding=llm_embedding, api_src=src_api_code ) logger.info(f"Init CrashAnalyzer") # 初始化 CrashAnalyzer,用于分析崩溃信息 crash_analyze_agent = crash_analyzer.CrashAnalyzer( llm = llm_analyzer, llm_embedding=llm_embedding, query_tools=query_tools,# 包含 test_case_index 和 cwe_index,用于检索测试用例和 CWE 信息。 api_src=src_api_code, use_memory=False )
7、生成 fuzz 程序(skip)
这步可使用skip_gen_driver跳过。
「1」尝试获取或生成API组合,判断api文件是否存在 ->agents_results/api_combine.json,如果存在直接加载 API 组合。不过这个API联合体最开始是需要LLM来生成的,如果对项目熟悉的话,也是可以自己写API组合的。
「2」生成API组合,调用plan_agent.api_combination。
「3」生成 Fuzz 测试程序,调用gen_agent.driver_gen()。
「4」设置input_agent的API组合信息,用于后续输入生成阶段(生成输入值、调用链等)。
「5」把 fuzz 驱动复制到 Docker 的共享目录。
# fuzzing_llm_engine/fuzzing.py # main() # 初始化完成,开始组合 API logger.info(f"Then generation agents starts combining API") # 创建 Agent 结果存储的目录 os.makedirs(agents_result_dir, exist_ok=True) # 生成模糊测试驱动 if args.gen_driver: # 1. 获取组合 API 列表 # 判断 api 文件是否存在 -> agents_results/api_combine.json # 存在就读取,否则从 api_list 提取 api 联合体并写入 api_combine_file = os.path.join(agents_result_dir, "api_combine.json") if os.path.exists(api_combine_file): logger.info("Loading existing API combination from api_combine.json") with open(api_combine_file, 'r') as f: api_combine = json.load(f) else: logger.info("Generating new API combination") # LLM 生成 API 联合体 api_combine = plan_agent.api_combination(api_list) with open(api_combine_file, 'w') as f: json.dump(api_combine, f) # 2. 生成 Fuzz 测试程序 logger.info("The generation agents starts generating fuzzing driver") fuzz_gen_code_output_dir = os.path.join(fuzz_projects_dir, "fuzz_driver") os.makedirs(fuzz_gen_code_output_dir, exist_ok=True) gen_agent.use_memory = False gen_agent.driver_gen(api_combine, src_api_code, api_summary, fuzz_gen_code_output_dir,project_name) else: logger.info("Skip Generating Fuzz Driver") api_combine = json.load(open(os.path.join(agents_result_dir, "api_combine.json"))) # 设置生成 InputGenerationAgent 的api_combination input_agent.set_api_combination(api_combine) # 把之前生成的 fuzz_driver 复制到 work_dir/docker_shared/fuzz_driver/{project_name}/ os.makedirs(os.path.dirname(work_dir+f"docker_shared/fuzz_driver/{project_name}/"), exist_ok=True) try: shutil.copytree(fuzz_projects_dir+"/fuzz_driver", work_dir+f"docker_shared/fuzz_driver/{project_name}/", dirs_exist_ok=True) logger.info(f"Copied fuzz drivers successfully.") except Exception as e: logger.error(f"Error copying fuzz drivers: {e}") exit()
api_combination
传入的api_list中每一个 API,使用 LLM 结合代码图谱信息,生成建议的 API 调用组合,返回多个组合结果列表。
「1」创建查询引擎和响应格式化器;combine_query_engine: 支持混合检索模式的代码图谱查询器。response_format_program: 将 LLM 的原始自然语言回答格式化为结构化对象。
「2」遍历输入的 API 列表,对每个 API 生成组合建议:
◆构造初始提问语句,提示词传入:当前要组合的 API;所有 API 列表;API 的使用频次信息(api_usage_count)
◆检查是否启用上下文,如果开启则:将上下文拼接进新的提问语句中,形成增强型提问
◆combine_query_engine.query(question)调用 LLM 进行代码知识图谱问答
◆response_format_program再次调用LLM调用,将回答格式化为结构化对象
「3」将本轮问答保存到向量记忆中,以便后续使用历史上下文
「4」将当前 API 添加到组合结果中(这里需要注意的是:会将当前指定的 API 再次加入 API 组合中,所以之后想要使用该 API 组合就需要去重),更新 API 使用次数记录。
# 利用 LLM 结合代码知识图谱检索器,生成建议的 API 组合 def api_combination(self, api_list): # 用于存储所有 API 的组合结果 api_combination = [] Settings.llm = self.llm Settings.embed_model = self.llm_embedding # 创建查询引擎 combine_query_engine = get_query_engine( self.code_graph_retriever, # 代码图谱的检索器 "HYBRID", # 混合检索模式 self.llm, get_response_synthesizer(response_mode="compact", verbose=True) # 精简回答模式 ) # 创建一个用于格式化 LLM 原始响应的格式化器,将其转换为结构化的 APICombination 对象 response_format_program = LLMTextCompletionProgram.from_defaults( output_cls=APICombination, prompt_template_str="The input answer is {raw_answer}. Please reformat the answer with two key information, the API combination list and the reason.", llm=self.llm ) # 遍历输入的 API 列表,对每个 API 生成组合建议 for api in tqdm(api_list): # 构造初始问题,格式化模板中包含当前 API、完整 API 列表、使用次数统计 # Patch question = self.api_combination_query_mowen.format( api=api, api_list=api_list, api_usage=json.dumps(self.api_usage_count) ) logger.info(f"API Combination, Init Question: {question}") logger.info(f"Use historical context: {self.use_memory}") # 如果使用上下文历史信息 if self.use_memory: # 根据当前问题从 memory 中获取相关历史消息 memory_chamessage = self.composable_memory.get(question) logger.info(f"Fetch historical context according to the init question: {memory_chamessage}") # 如果有历史上下文信息,则合并到问题中 if len(memory_chamessage): memory_chamessage = "\n".join([str(m) for m in memory_chamessage]) # 构造包含上下文的新问题 question = self.api_combination_query_with_memory.format( api=api, memory_context=memory_chamessage, api_list=api_list, api_usage=json.dumps(self.api_usage_count) ) logger.info("New question with the historical context") logger.info(question) # 调用 LLM response_obj = combine_query_engine.query(question) # 将原始响应转为结构化格式(包含 api_combination 和 reason) # LLM 再次处理响应格式 ''' PS : 这里再次调用 LLM 的时候,可能会因为回答不标准导致报错 , Pydantic 解析不匹配定义的模型结构,导致 ValidationError class APICombination(BaseModel): api_combination: List[str] api_combination_reason: str ''' logger.debug(f"mowen response_obj:\n{response_obj}") response_format = response_format_program(raw_answer=response_obj.response) response = response_format.api_combination logger.info(f"API Combination response_obj:\n{response_obj}\n{response_format}\n{response}\n") # 将本轮问答保存到向量记忆中,以便后续使用历史上下文 query_answer = [ ChatMessage.from_str(question, "user"), ChatMessage.from_str(f"{response_obj.response}", "assistant"), ] self.vector_memory.put_messages(query_answer) # 如果响应为空,转为空列表 if response == "Empty Response": response = [] # 将当前 API 添加到组合结果中 response.append(api) api_combination.append(response) # Update API usage count # 更新 API 使用次数记录 self.update_api_usage_count(response) return api_combination
Patch
正常的回答应该是这样的

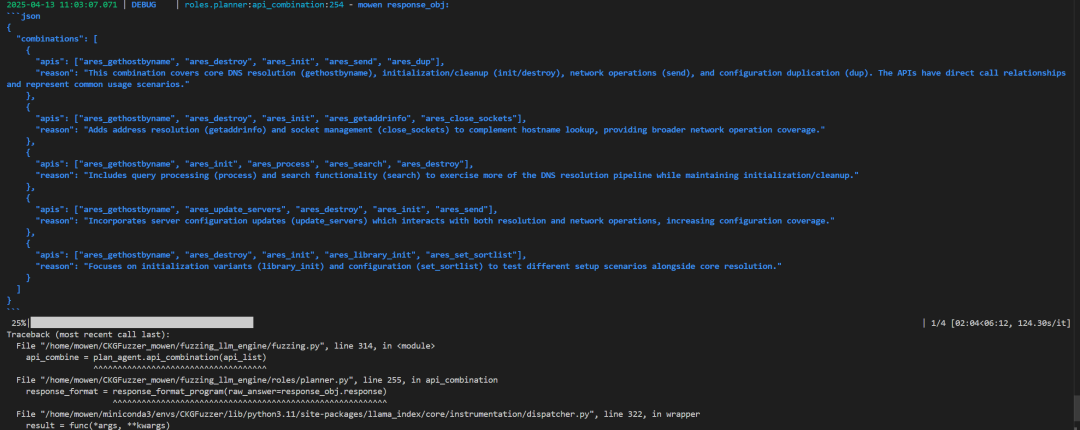
解决方案:
1、添加历史记录以供参考
2、添加 try catch 循环处理报错
3、提供更好的 prompt
这里进行 prompt 重写
prompt 重写如下
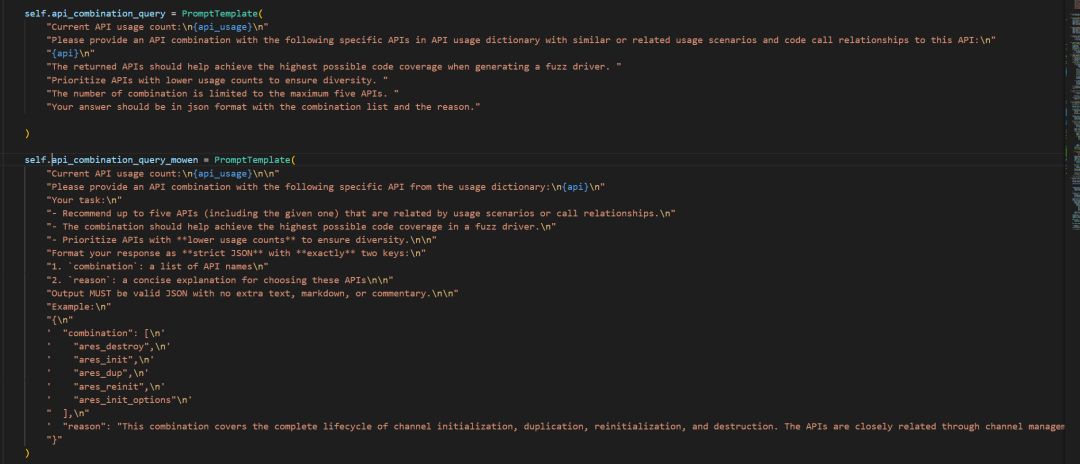
构造问题采用api_combination_query_mowen
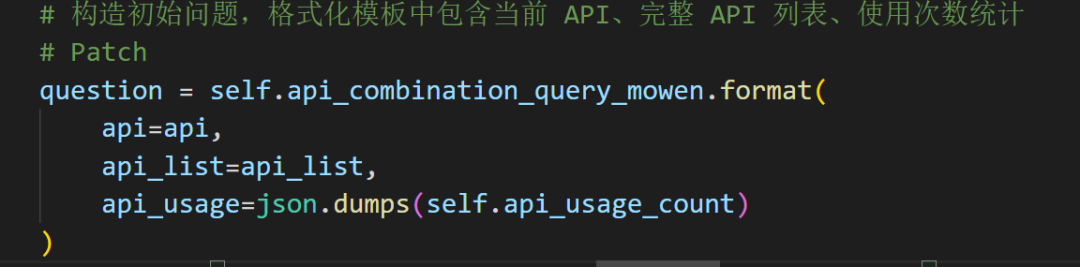
{ "combination": [ "ares_destroy", "ares_init", "ares_dup", "ares_reinit", "ares_init_options" ], "reason": "This combination covers the complete lifecycle of channel initialization, duplication, reinitialization, and destruction. The APIs are closely related through channel management operations and share common internal calls. Selecting these lower-usage-count APIs together ensures comprehensive coverage of channel state handling while maintaining diversity in the fuzz driver." }
driver_gen
根据 API 组合,利用 LLM 自动生成 fuzz driver 源代码文件,用于后续模糊测试。
「1」遍历API组合列表 , 因为在生成API组合的时候,会将当前指定的 API 再次加入 API 组合中,所以这里,做了 API 的去重。
「2」从api_summary中查找描述,从api_code中获取源码
「3」调用fuzz_driver_generation(),根据提供的 API 信息(源码、摘要),项目名称 自动生成 fuzz driver。
「4」从 LLM 返回内容(一般都为 Markdown格式)中提取出 C/C++ 代码。这里调用extract_code()利用正则匹配代码块即可。
# fuzzing_llm_engine/roles/fuzz_generator.py # 根据 API 组合结果,生成对应的 fuzz driver,并保存为文件 def driver_gen(self, api_combination, api_code, api_summary, fuzz_gen_code_output_dir,project): i = 1 # 遍历 API 组合列表 # 1. 获取 API 源代码 # 2. 获取 API 描述 # 3. 生成 fuzz driver # 4. 保存 fuzz driver 为文件 for api_list in api_combination: api_list = list(set(api_list)) # 去重,防止同一个 API 被重复使用(因为在生成API联合体时,会把API再次添加) api_list_proc = [] # 实际处理成功的 API 列表 api_info = "" # 存储 API 的源码片段 api_sum = "" # 存储 API 的功能摘要 for api in api_list: for file_key in api_summary.keys(): summary = api_summary[file_key].get(api, None) if summary: single_api_sum = f"{api}:\n{summary}" single_api_info = f"{api}:\n{api_code[api]}" api_sum = "\n".join([api_sum, single_api_sum]) api_info = "\n".join([api_info, single_api_info]) api_list_proc.append(api) break if api_list_proc: # self.headers -> config 配置文件中的头文件列表 fuzz_driver_generation_response = self.fuzz_driver_generation(api_list_proc, api_info, self.headers, api_sum) # 从 LLM 返回内容(一般都为 Markdown格式)中提取出 C/C++ 代码 fuzz_driver_generation_response = self.extract_code(str(fuzz_driver_generation_response)) logger.info(fuzz_driver_generation_response) model_name = self.llm_coder.model.replace(":", "_") fuzzer_name = f"{project}_fuzz_driver_{self.use_memory}_{model_name}_{i}.{self.file_suffix[self.language.lower()]}" with open(os.path.join(fuzz_gen_code_output_dir, fuzzer_name), "w") as f: f.write(fuzz_driver_generation_response) i += 1 else: return False
fuzz_driver_generation
根据提供的 API 信息(源码、摘要),项目名称 自动生成 fuzz driver。
# fuzzing_llm_engine/roles/fuzz_generator.py def fuzz_driver_generation(self, api_list, api_info, headers, api_sum): ''' 根据提供的 API 信息(源码、摘要),项目名称 自动生成 fuzz driver。 参数: api_list: 组合中使用的 API 名称列表 api_info: 这些 API 的源码拼接文本 headers: 请求中使用的头部信息(config中的headers) api_sum: 这些 API 的摘要文本 返回: fuzz_driver_generation_response: 生成的 fuzz driver 代码(字符串形式) ''' question = self.fuzz_driver_generation_prompt.format(lang=self.language, api_list=api_list, headers=headers, api_info=api_info, api_sum=api_sum) if self.use_memory: memory_chamessage = self.composable_memory.get(question) if len(memory_chamessage): memory_chamessage = "\n".join([str(m) for m in memory_chamessage]) question = self.fuzz_driver_generation_prompt_with_memory.format(lang=self.language, api_list=api_list, memory_context=memory_chamessage, headers=headers, api_info=api_info, api_sum=api_sum) logger.info("Question:") logger.info(question) # 调用 LLM coder版本 来生成测试程序 fuzz_driver_generation_response = self.llm_coder.complete(question).text logger.info("Generated Fuzz Driver:") logger.info(fuzz_driver_generation_response) query_answer = [ ChatMessage.from_str(question, "user"), ChatMessage.from_str(fuzz_driver_generation_response, "assistant"), ] self.vector_memory.put_messages(query_answer) return fuzz_driver_generation_response
8、检查编译(skip)
这步可使用skip_check_compilation跳过。
「1」先启动检查编译使用的docker。完成这步docker已经启动了,并且已经编译好了libfuzzer和项目。接下来就会对target_fuzz程序进行编译检测。
「2」调用check_compilation()来检查之前生成的fuzz程序是否能过编译。
# 启动检查编译使用的 docker if not start_docker_for_check_compilation(work_dir, project_name): logger.info("Failed to start docker for check compilation") exit() # 检查编译 if args.check_compilation: logger.info("Check Compilation") fix_agent.check_compilation(shared_dir, project_name, file_suffix=["c","cc"]) else: logger.info("Skip Check Compilation")
检查编译过程展示
处理编译报错的情况
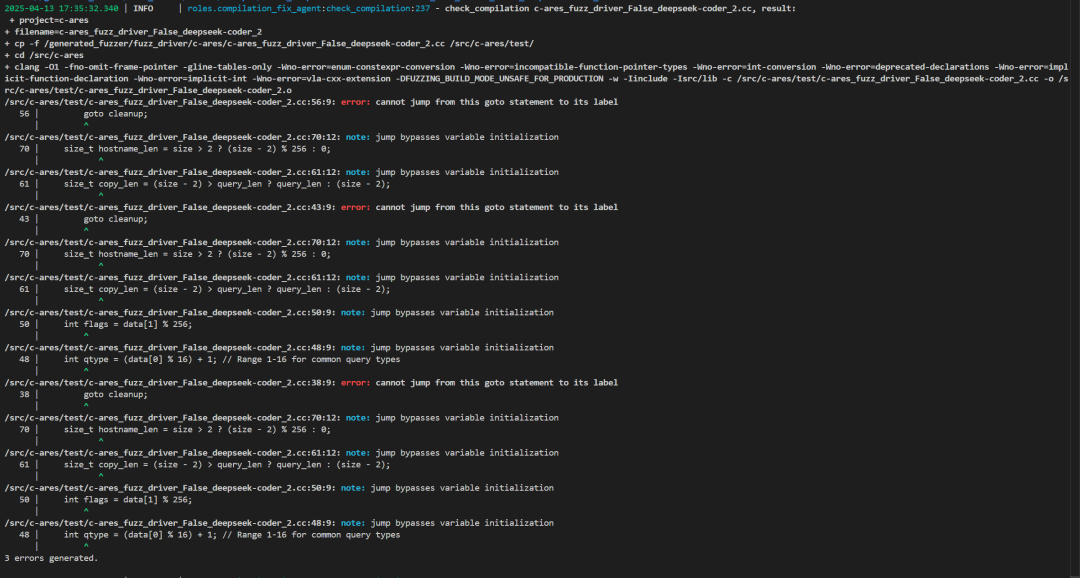
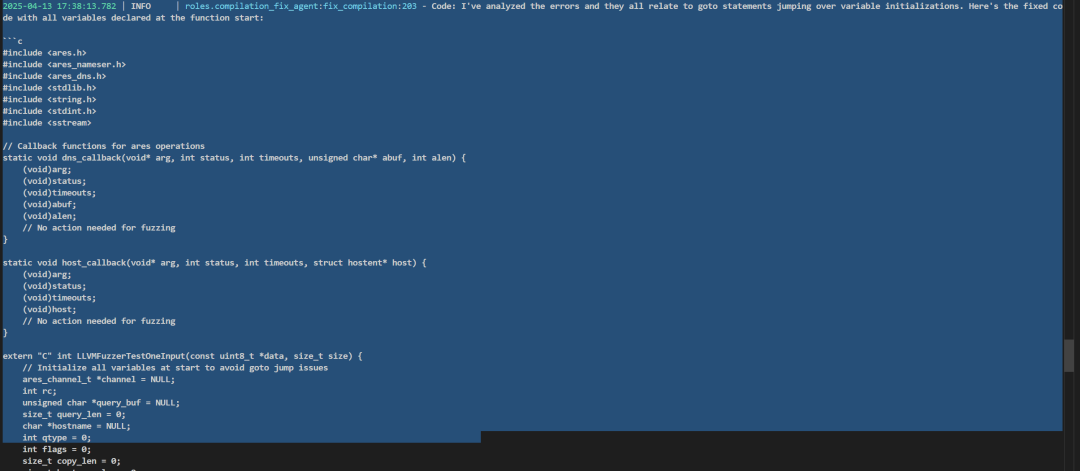
有 5 次试错机会,第一次就 fix 成功
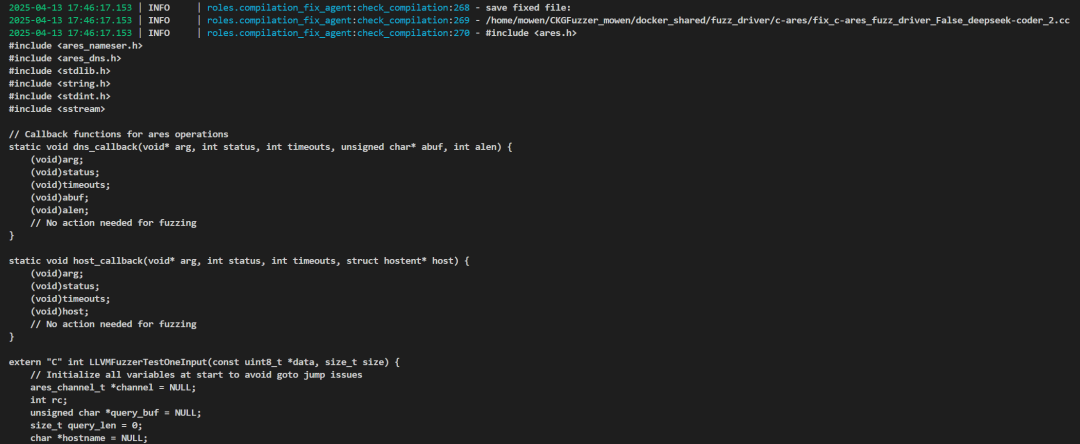
生成的其他样本都没有问题,编译可以直接通过
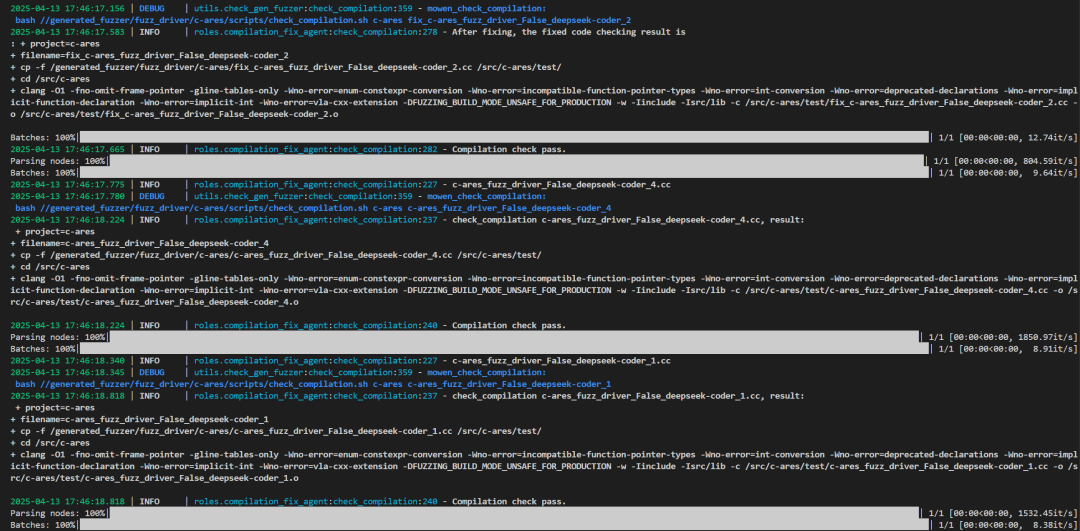
start_docker_for_check_compilation
PS:相关于Docker的操作基本都是用的OSS-FUZZ框架,师傅们这边可以选择跳过。
构建脚本为oss-fuzz中的 infra/helper.py
google/oss-fuzz: OSS-Fuzz - continuous fuzzing for open source software.
OSS-Fuzz 使用:Code coverage | OSS-Fuzz
启动一个 Docker 准备检查 fuzz 代码是否可以成功编译
def start_docker_check_compilation_impl( # pylint: disable=too-many-arguments,too-many-locals,too-many-branches project, # 项目信息(包含路径、名称等) engine, # 模糊测试引擎(如 libfuzzer、centipede) sanitizer, # 使用的 sanitizer 类型(如 address、undefined) architecture, # CPU 架构(x86_64、aarch64 等) env_to_add, # 额外的环境变量 source_path, # 源码路径(用于挂载进容器) generation_fuzzing_driver_folder, # 存放生成型 fuzz 驱动的目录 mount_path=None, # 挂载点路径(容器中的路径) child_dir='', # 构建输出的子目录 build_project_image=True # 是否构建项目镜像 ): """Builds fuzzers.""" # 构建 Docker 镜像 if build_project_image and not build_image_impl(project, architecture=architecture): return False # 确保 sanitizer 是字符串 if isinstance(sanitizer, list): sanitizer_str = ','.join(sanitizer) else: sanitizer_str = sanitizer project_out = os.path.join(project.out, child_dir) env = [ 'FUZZING_ENGINE=' + engine, 'SANITIZER=' + sanitizer_str, 'ARCHITECTURE=' + architecture, 'PROJECT_NAME=' + project.name, 'HELPER=True', ] # 如果当前环境是 CI,会加上 OSS_FUZZ_CI 标志 _add_oss_fuzz_ci_if_needed(env) if project.language: env.append('FUZZING_LANGUAGE=' + project.language) if env_to_add: env += env_to_add # 设置环境遍历 需要前置 -e # 形如 -> ['-e', 'FUZZING_ENGINE=libfuzzer', '-e', 'SANITIZER=address', ...] command = _env_to_docker_args(env) if source_path: # 从 Dockerfile 中获取工作目录 workdir = _workdir_from_dockerfile(project) # 设置 挂载路径 -> ['-v', '{source_path}:{mount_path}'] if mount_path: command += [ '-v', '%s:%s' % (_get_absolute_path(source_path), mount_path), ] else: # OSS-Fuzz 的 /src 通常是由远程下载构建 if workdir == '/src': logger.error('Cannot use local checkout with "WORKDIR: /src".') return False command += [ '-v', '%s:%s' % (_get_absolute_path(source_path), workdir), ] # Check if the gcr.io/oss-fuzz/{project.name} image exists # 如果本地存在构建好的 gcr.io/oss-fuzz/{project.name} 镜像,就用它 # 否则使用本地的 {project.name}_base_image。 # 查看名为 'gcr.io/oss-fuzz/{project.name}' 的 Docker 镜像的详细元信息 if subprocess.run(['docker', 'image', 'inspect', f'gcr.io/oss-fuzz/{project.name}'], capture_output=True).returncode == 0: image_name = f'gcr.io/oss-fuzz/{project.name}' else: # If not, use the {project.name}_base_image image_name = f'{project.name}_base_image' command += [ '--name', project.name+"_check", '-v', f'{project_out}:/out', '-v', f'{project.work}:/work', '-v', f'{generation_fuzzing_driver_folder}:{LLM_WORK_DIR}', '-dit', image_name, '/bin/bash' ] # if sys.stdin.isatty(): # command.insert(-1, '-d') # 启动 Docker result = docker_start(command, architecture=architecture) # with open("/home/mawei/Desktop/work1/wei/fuzzing_llm/fuzzing_os/oss-fuzz-modified/build_fuzzers.txt", "a") as f: # f.write(print_docker_run(command, # architecture=architecture) +"\n") if not result: logger.error('Building fuzzers failed.') return False # 进入 Docker , 执行 compile 命令 ,编译项目 -> /src/<project>/build.sh compile_command =["compile"] result=docker_exec_command(compile_command,project.name) logger.info(result) return True
「1」先检查project_name的容器是否正在运行,检测语句形如:
docker ps --filter name=f"{project_name}_check" --format {{.Names}}
「2」如果容器不在运行,则利用check_gen_fuzzer.py脚本启动 docker
# 启动一个 Docker 准备检查 fuzz 代码是否可以成功编译 def start_docker_for_check_compilation(project_dir, project_name):
# 检测 project_name 的容器是否正在运行 if is_docker_container_running(project_name): logger.info(f"Docker container '{project_name}_check' is already running. Continuing...") return True else: # 如果不在运行, 启动一个 Docker logger.info(f"Docker container '{project_name}_check' is not running. Starting...") try: # 利用 check_gen_fuzzer.py 脚本启动 docker # 没做 docker images 是否已经存在的检查 docker_start_command = f"python {project_dir}fuzzing_llm_engine/utils/check_gen_fuzzer.py start_docker_check_compilation {project_name} --fuzzing_llm_dir {project_dir}docker_shared/" logger.debug(f"docker_start_command: \n{docker_start_command}") subprocess.run(shlex.split(docker_start_command), check=True) logger.info("Docker for check compilation started successfully.") return True except subprocess.CalledProcessError as e: logger.info(f"Error starting Docker for check compilation: {e}") return False
在 check_gen_fuzzer.py中通过start_docker_check_compilation会调用到start_docker_daemon()
start_docker_daemon()是start_docker_check_compilation_impl()的封装,所以我们直接看start_docker_check_compilation_impl()
在指定架构下,配置并启动一个 Docker 容器,根据提供的 fuzzing 引擎和 sanitizer,对给定项目进行构建验证(编译 check)。
「1」构建项目镜像(拉取),会指定项目中的Dockerfile进行拉取
docker build -t gcr.io/oss-fuzz/c-ares --file /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/projects/c-ares/Dockerfile /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/projects/c-ares
「2」处理sanitizer、这里指定的sanitizer就是libfuzzer中的fsanitize参数。
「3」构建环境变量,因为环境变量使用时需要前置-e,通过调用_env_to_docker_args()转换为以下类似的语法方便调用:
['-e', 'SANITIZER=address', ...]
环境变量名
示例值
作用说明
备注
FUZZING_ENGINE
libfuzzer
指定使用的模糊测试引擎,用于控制编译逻辑和运行方式。
如:libfuzzer、afl++等
SANITIZER
address
使用的 Sanitizer 类型,用于运行时检测内存/未定义行为错误。
可多个组合,如address,undefined
ARCHITECTURE
x86_64
架构类型,决定在何种硬件平台或模拟器上进行构建和运行。
如:x86_64、aarch64
PROJECT_NAME
c-ares
当前项目名称,在路径、日志等构建中使用。
与项目结构密切相关
HELPER
True
标记该容器为辅助容器(如用于构建/验证),而不是执行 fuzz 测试的主容器。
控制某些构建逻辑分支
「4」 配置挂载文件夹,这里默认会挂载三个文件夹:out、work、generated_fuzzer。
本地路径(宿主机)
容器内路径
目录类型
作用说明
fuzzing_llm_engine/build/out/{project}/
/out
输出目录
用于保存编译后生成的 fuzzing 二进制文件(如 fuzzer 可执行程序) fuzz的各种结果。并且包含 work 目录。
fuzzing_llm_engine/build/work/{project}/
/work
工作目录
构建过程中fuzz程序的中间.o文件,并存放用于fuzzer的种子。
docker_shared/
/generated_fuzzer
输入目录
存放一些构建脚本等,供容器内编译脚本读取并集成进项目。
「5」调用docker_start()执行配置好的语句,来启动Docker。下面是一个测试样例。
docker run --privileged --shm-size=2g --platform linux/amd64 \ -e FUZZING_ENGINE=libfuzzer \ -e SANITIZER=address \ -e ARCHITECTURE=x86_64 \ -e PROJECT_NAME=c-ares \ -e HELPER=True \ -e FUZZING_LANGUAGE=c++ \ --name c-ares_check \ -v /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/build/out/c-ares/:/out \ -v /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/build/work/c-ares:/work \ -v /home/mowen/CKGFuzzer_mowen/docker_shared/:/generated_fuzzer \ -dit gcr.io/oss-fuzz/c-ares /bin/bash
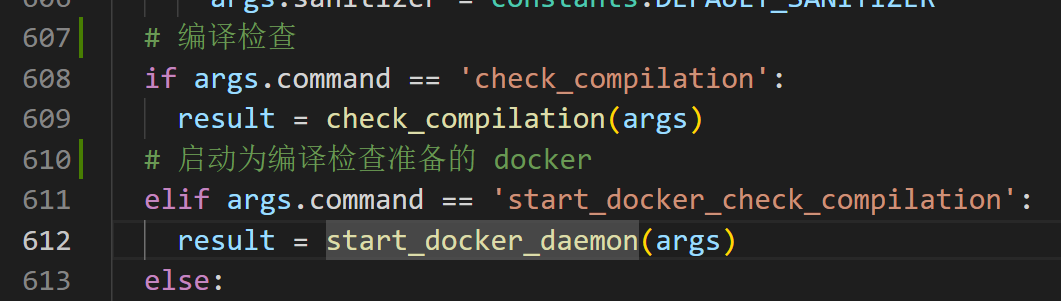
start_docker_check_compilation_impl
docker exec -u root -it c-ares_check compile
到此docker已经启动了,并且已经编译好了libfuzzer和项目。接下来就会对target_fuzz程序进行编译检测。
check_compilation
用于检查目录下 fuzz 驱动文件的编译情况,并自动尝试修复
整个函数执行的流程还是比较清晰的,大致流程图如下。
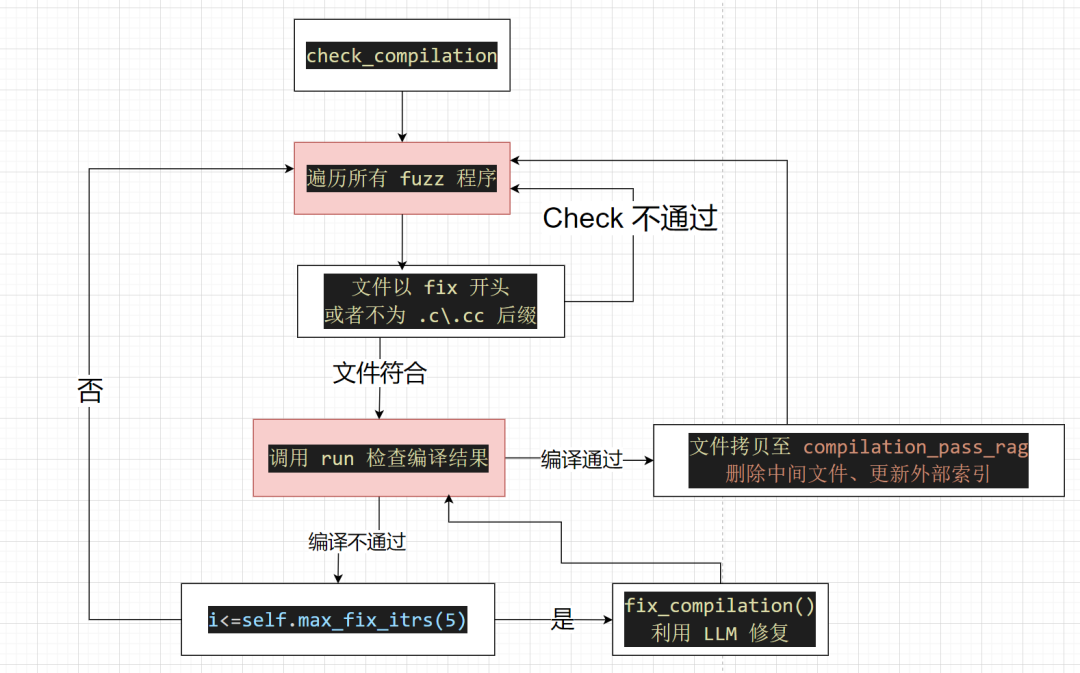
# fuzzing_llm_engine/roles/compilation_fix_agent.py # 用于检查指定目录下 fuzz 驱动文件的编译情况,并在必要时自动尝试修复 def check_compilation(self, directory, project, file_suffix): # 编译通过的目录 -> compilation_pass_rag if not os.path.exists(directory+f"fuzz_driver/{project}/compilation_pass_rag/"): os.makedirs(directory+f"fuzz_driver/{project}/compilation_pass_rag/") logger.info(directory+f"fuzz_driver/{project}/") # 临时目录 fix_tmp 存放待检查和修复的 fuzz 驱动文件 fix_tmp = os.path.join(directory, f"fuzz_driver/{project}/") os.makedirs(fix_tmp, exist_ok=True) # 获取项目 fuzz 驱动目录下所有的文件(不递归) all_items = os.listdir(directory + f"fuzz_driver/{project}/") files = [item for item in all_items if os.path.isfile(os.path.join(directory, f"fuzz_driver/{project}/", item))] # files 为所有待测试编译的文件 logger.info(files) for file in files: # 跳过 fix 文件 if file.startswith("fix"): continue logger.info(file) # 加载 fuzz 驱动文件 with open(directory+f"fuzz_driver/{project}/"+file,"r") as fr: code=fr.read() # 获取文件后缀 f_suffix = file.split(".")[-1] if f_suffix in file_suffix: # Modify this to match your desired file types run_args = ["check_compilation", project, "--fuzz_driver_file", file] # 利用 check_gen_fuzzer.py result = run(run_args) logger.info(f"check_compilation {file}, result:\n {result}") if "error:" not in result: # 如果编译没有任何错误 logger.info('Compilation check pass.') # 拷贝 fuzz 文件到 compilation_pass_rag 目录下 shutil.copy(directory+f"fuzz_driver/{project}/"+file, directory+f"fuzz_driver/{project}/compilation_pass_rag/") # Remove the corresponding .o file if it exists # 删除编译的 .o 文件 base_name = os.path.splitext(file)[0] object_file = f"{base_name}.o" object_file_path = os.path.join(directory, f"fuzz_driver/{project}/", object_file) if os.path.exists(object_file_path): os.remove(object_file_path) logger.info(f"Removed object file: {object_file_path}") self.update_external_base(code) else: # 编译有报错情况 i=1 # 最多处理 5 次 while i<=self.max_fix_itrs: logger.warning(f'compilation errors -> {file} has {i} ') # LLM 生成修复代码 fxi_code_raw = self.fix_compilation(error=result,code=code) input(f"{logger.debug('mowen')}") # 提权 Markdown 中的代码 fix_code = extract_code(fxi_code_raw) if fix_code == "No code found": logger.info(fxi_code_raw) i = self.max_fix_itrs + 1 continue code = fix_code fixed_file_name = f"fix_{file}" # 写入到文件中( fix_ ) with open(f"{fix_tmp}/{fixed_file_name}","w") as fw: logger.info("save fixed file:") logger.info(directory+f"fuzz_driver/{project}/{fixed_file_name}") logger.info(fix_code) fw.write(fix_code) # logger.info("Done Write") # 再次编译测试 run_args = ["check_compilation", project, "--fuzz_driver_file", fixed_file_name] result = run(run_args) msg =[ ChatMessage.from_str(result, "user") ] logger.info(f"After fixing, the fixed code checking result is \n: {result}") self.composable_memory.put_messages(msg) if "error:" not in result: # fix 后的代码编译成功 # pdb.set_trace() logger.info('Compilation check pass.') shutil.copy(f"{fix_tmp}/{fixed_file_name}", directory+f"fuzz_driver/{project}/compilation_pass_rag/") base_name = os.path.splitext(fixed_file_name)[0] object_file = f"{base_name}.o" object_file_path = os.path.join(directory, f"fuzz_driver/{project}/", object_file) if os.path.exists(object_file_path): os.remove(object_file_path) logger.info(f"Removed object file: {object_file_path}") self.update_external_base(code) os.remove(directory+f"fuzz_driver/{project}/{fixed_file_name}") break os.remove(directory+f"fuzz_driver/{project}/{fixed_file_name}") # 最后都会删除生成的 fix 文件 i+=1
「1」创建编译通过的目录 ->compilation_pass_rag。完成其他目录的初始化工作。
「2」遍历所有的fuzz驱动程序,需要跳过fix文件,文件后缀不为.c\.cc的target_fuzz。
「3」调用 fuzzing_llm_engine/utils/check_gen_fuzzer.py中的run()函数来编译target_fuzz(最终会执行下面的脚本,就是对之前启动的docker执行编译语句),根据编译返回的结果中是否有error的字样来判断是否编译失败。
#!/bin/bash set -x project=$1 filename=$2 cp -f /generated_fuzzer/fuzz_driver/${project}/${filename}.cc /src/${project}/test/ cd /src/${project} # [ -d /generated_fuzzer/syntax_check_tmp ] || mkdir -p /generated_fuzzer/syntax_check_tmp #clang -fsyntax-only -w -Wnote -Wextra -pedantic -Iinclude -Isrc/lib /src/${project}/test/${filename} $CC $CFLAGS -w -Iinclude -Isrc/lib -c /src/${project}/test/${filename}.cc -o /src/${project}/test/${filename}.o
「4」如果编译不通过,则调用fix_compilation()来使用LLM自动修复,修复后还会判断是否编译失败,默认编译失败上限为5次。超过5次就会抛弃该测试样例。
「5」对于编译通过的,会将编译通过的文件拷贝至compilation_pass_rag以供后续测试使用。
fix_compilation
来看看LLM是怎么进行自动修复的。这里需要注意的是,初始化fix_agent的时候是带有编译成功的文件索引的。当提问的时候,会检索query_tools中相关索引,比如检索test_case_index中最相关的fuzz测试函数片段。
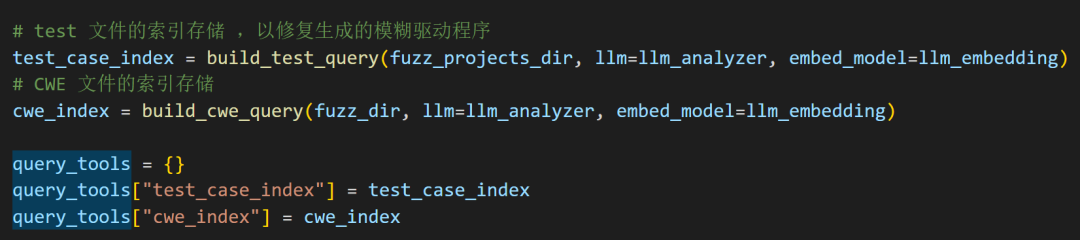
「1」第一次调用 LLM 提取错误信息对应的代码片段。把错误片段格式化成新的问题,如果使用提取错误信息失败,则使用原始的错误信息。
「2」第二次调用 LLM 用来先生成一个example,这步并不会修复,只是生成了一个修复样例,好处就是容错性更好了。
「3」第三次调用 LLM 生成修复代码,这步返回真正的fix code,只需要提取返回 Markdown 中的代码,就拿到最终修复的代码了。
# fuzzing_llm_engine/roles/compilation_fix_agent.py # 自动修复代码编译错误 def fix_compilation(self, error, code): # LLM 提取错误信息对应的代码片段 summarized_error = self.summarize_errors(error) # LLM 给出修复样例 try: retrieve_example_question = self.fix_compilation_query.format(fuzz_driver=code, error=summarized_error) example = self.driver_query_engine.query(retrieve_example_question) except: # Fallback to using original error if query fails # 如果使用提取错误信息失败,则使用原始的错误信息 retrieve_example_question = self.fix_compilation_query.format(fuzz_driver=code, error=error) example = self.driver_query_engine.query(retrieve_example_question) # prompt 设置 question = self.fix_compilation_prompt.format(fuzz_driver=code, error=error, example=example) if self.use_memory: if len(self.composable_memory.get_all()) != 0: context_memory = self.composable_memory.get(self.fix_compilation_query.format(fuzz_driver=code, error=summarized_error)) question = self.fix_compilation_prompt_with_memory.format(fuzz_driver=code, context_memory=context_memory, error=error, example=example) logger.info(f"Use model {self.llm_coder.model} to fix code") logger.info(f"Question: {question}") # LLM 生成修复代码 fix_code = self.llm_coder.complete(question).text msgs = [ ChatMessage.from_str(question, "user"), ChatMessage.from_str(fix_code, "assistant") ] logger.info(f"Code: {fix_code}") self.composable_memory.put_messages(msgs) return fix_code
Patch
执行 check_compilation.sh 脚本 来检查编译是否通过
由该脚本又引发一个问题,脚本中固定文件后缀为.c拷贝到/src/{project}/test/下
然后在进行编译检查
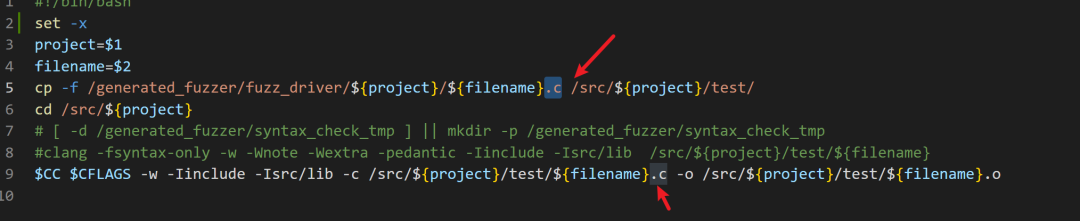
但是生成的fuzz程序后缀为.cc,所以就会造成拷贝失败

解决方案:
1、取消sh脚本中的固定.c后缀,对应的在脚本中也不要去除后缀即可正常拷贝编译

2、修改sh脚本中后缀为.cc
这步可使用skip_gen_input跳过。
「1」调用input_agent.generate_input_fuzz_driver()让Agent生成尽可能覆盖多路径的种子。
读取源码文件,生成一个用于 fuzz 测试的初始输入 seed,并将其保存到指定目录中
「1」遍历所有能够编译成功的target_fuzz
「2」调用generate_input()根据源代码和提取的 ID ( 这里提供的 ID 对应 API 组合)生成一个 fuzz 测试初始输入种子。
「3」保存种子到{fuzzer_name}_corpus文件夹中。
# fuzzing_llm_engine/roles/input_gen_agent.py # 读取源码文件,生成一个用于 fuzz 测试的初始输入 seed,并将其保存到指定目录中 def generate_input_fuzz_driver(self, file_path): with open(file_path, 'r', encoding='utf-8') as f: # 读取源码文件 source_code = f.read() # 从文件名中提取数字 ID : driver_12.cpp -> 12 file_id = self.extract_number_from_filename(file_path) # 根据源代码和提取的 ID 生成一个 fuzz 测试初始输入种子 input_seed = self.generate_input(source_code, file_id) logger.info(f"{file_path} Generate Input seed: {input_seed}") # 路径 /path/mowen.cpp # → file_name = mowen.cpp # → fuzzer_name = mowen file_name = os.path.basename(file_path) fuzzer_name = os.path.splitext(file_name)[0] logger.info(f"================ {fuzzer_name}") # 创建一个用于保存 corpus 的文件夹 corpus_folder = os.path.join(self.output_dir, f"{fuzzer_name}_corpus") os.makedirs(corpus_folder, exist_ok=True) # 生成 hash,并对该文件写入种子 hash_code_file = generate_hash(f"{fuzzer_name}_corpus.txt") logger.info(f"Save -> {corpus_folder}->{hash_code_file}.txt") with open(os.path.join(corpus_folder, f"{hash_code_file}.txt"), 'w', encoding='utf-8') as f: f.write(input_seed)
根据源码、静态分析数据流图(DFG)和相关 API 生成用于 Fuzz 的输入种子
「1」调用dfg_analysis()通过LLM对源代码分析得到DFG,挖掘出代码的数据依赖结构。LLM后续可以基于DFG理解代码结构与变量流向。
「2」通过dfg、source_code、api_signature构造prompt,然后发送给LLM,让其生成raw的输入种子
「3」让 LLM重新格式化这个raw输出,提取出input + reason,如果失败,就把raw文本解析为InputSeed对象,并降级使用原始输出。
# 根据源码、静态分析数据流图(DFG)和相关 API 生成用于 Fuzz 的输入种子 def generate_input(self, source_code, api_combination_index): # LLM 对源代码进行数据流图(DFG),得到代码的数据依赖结构 dfg = self.static_analyzer.dfg_analysis(source_code) # 通过文件 ID 定位 api 联合体 api_list = self.api_combine[api_combination_index-1] api_signature = "" for api in api_list: if api in self.api_src.keys(): # 提取 API 的函数签名 api_signature_single = f"{api}:\n{self.extract_function_signature(self.api_src[api])}" api_signature = "\n".join([api_signature,api_signature_single]) else: continue logger.info(f"api_signature:\n{api_signature}") # prompt format question = self.generate_input_prompt.format(dfg=dfg,source_code=source_code,api_signature=api_signature) if self.use_memory: memory_context = self.composable_memory.get(question) question = self.generate_input_prompt_with_memory.format(dfg=dfg, memory_context=memory_context,source_code=source_code,api_signature=api_signature) # LLM 生成输入种子 raw_input_seed = self.llm.complete(question).text logger.info(f"raw_input_seed:\n{raw_input_seed}") try: # llm 格式化为 : 输入种子和原因 input_seed = self.input_seed_generator(raw_input_seed=raw_input_seed) except Exception as e: # 如果失败则用原始输入 input_seed = InputSeed(input_seed=raw_input_seed, explanation=str(e)) question = self.generate_input_prompt.format(dfg=dfg,source_code=source_code,api_signature=api_signature) msgs =[ ChatMessage.from_str(question, "user"), ChatMessage.from_str(raw_input_seed, "assistant") ] self.composable_memory.put_messages(msgs) # pattern = r'```(.*?)```' # match = re.search(pattern, input_seed, re.DOTALL) # if match: # input_seed=match.group(1) # else: # input_seed="None" logger.info(f"input_seed:\n{input_seed.input_seed}") return input_seed.input_seed
在完成以上所有准备工作之后,项目终于进入了fuzz阶段。如果此时只是简单地对之前生成的target_fuzz进行表面包装来开展fuzz测试,那么整个项目的质量势必会大打折扣。因为对于这个项目而言,fuzz阶段的成效在很大程度上依赖于前期所做的大量准备工作,正是这些准备确保了能够生成高质量的target_fuzz,进而决定了最终是否能触发crash。
而CKGFuzzer的不同之处在于,它不仅进行分支覆盖率的统计,还能基于覆盖率判断是否需要对 API 进行优化。优化后的API会重新经过前面的所有流程,再用于新一轮的fuzz。CKGFuzzer的核心优势就在于极致地利用了LLM来生成高质量的测试程序,从而显著提升了整个项目的质量。
「1」初始化Fuzzer,几乎把之前的所有资源全部都融合进去了。调用build_and_fuzz()开始 fuzz。
9、生成输入种子(skip)
# fuzzing_llm_engine/fuzzing.py # 生成输入 if args.gen_input: logger.info("Generate Input") # 遍历已经通过的 fuzz_driver 目录 for root, dirs, files in os.walk(os.path.join(shared_dir, f"fuzz_driver/{project_name}/compilation_pass_rag/")): logger.info(files) for file in files: input_agent.generate_input_fuzz_driver(os.path.join(shared_dir+f"fuzz_driver/{project_name}/compilation_pass_rag/",file)) else: logger.info("Skip Generate Input")
generate_input_fuzz_driver
generate_input
10、Fuzz
build_and_fuzz
「1」遍历每个fuzz驱动程序,调用build_and_fuzz_one_file()对每个程序进行单独的fuzz。
其实对于一个项目进行 fuzz 的定时基本不会小于 24 小时,所以要对所有 fuzz驱动程序跑完整个流程,耗时也是成倍增长,所以这里使用build_and_fuzz_one_file()最好是多线程的批处理。能够极高提升fuzz的效率。
# fuzzing_llm_engine/roles/run_fuzzer.py def build_and_fuzz(self): fix_fuzz_driver_dir = os.path.join(self.directory, f"fuzz_driver/{self.project}/compilation_pass_rag/") if not os.path.exists(fix_fuzz_driver_dir): logger.info(f"No folder {fix_fuzz_driver_dir}") return # build_fuzzer_file logger.info(os.listdir(fix_fuzz_driver_dir)) # Check and remove the merge_report directory if it exists # 如果合并的报告已经存在,则删除(这步是必须的,因为后期要通过 merge_report 来判断是否继续优化 API 再次fuzz) merge_report_path = f"{self.report_dir}merge_report" if os.path.exists(merge_report_path): logger.info(f"Removing existing merge_report directory: {merge_report_path}") shutil.rmtree(merge_report_path) # 遍历每个 fuzz 驱动程序 for fuzz_driver_file in os.listdir(fix_fuzz_driver_dir): logger.info(f"Fuzz Driver File {fuzz_driver_file}") self.build_and_fuzz_one_file(fuzz_driver_file, fix_fuzz_driver_dir=fix_fuzz_driver_dir) logger.info(f"Failed builds: {self.failed_builds}")
build_and_fuzz_one_file
「1」初始化共组,获取API组合,确认fix fuzz driver文件夹存在,
「2」编译fuzz driver调用check_gen_fuzzer.py,最终会执行以下的命令,使用之前启动的c-ares_check的 Docker 作为编译环境,再调用entrancy.sh进行taget_fuzz编译的准备工作,为什么是说准备工作,后续会分析这个脚本,然后执行compile开始编译。然后这里编译失败,会直接跳过该文件,该阶段没有fix。
docker exec -u root -it c-ares_check \ /bin/bash -c bash \ /generated_fuzzer/fuzz_driver/c-ares/scripts/entrancy.sh fix_c-ares_fuzz_driver_False_deepseek-coder_2.cc c-ares && compile「3」启动fuzzer,调用语句如下,使用config.yaml中的time_budget来控制单个fuzz的最长时间(timeout),默认的镜像采用gcr.io/oss-fuzz-base/base-runner。
docker run --rm --privileged --shm-size=2g --platform linux/amd64 \ -i \ -e FUZZING_ENGINE=libfuzzer \ -e SANITIZER=address \ -e RUN_FUZZER_MODE=interactive \ -e FUZZING_LANGUAGE=c++ \ -e HELPER=True \ -e CORPUS_DIR=/tmp/fix_c-ares_fuzz_driver_False_deepseek-coder_2_corpus \ -v /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/build/work/c-ares/fix_c-ares_fuzz_driver_False_deepseek-coder_2_corpus:/tmp/fix_c-ares_fuzz_driver_False_deepseek-coder_2_corpus \ -v /home/mowen/CKGFuzzer_mowen/docker_shared/:/generated_fuzzer \ -v /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/build/out/c-ares:/out \ -t gcr.io/oss-fuzz-base/base-runner \ /bin/bash -c 'timeout 1m run_fuzzer fix_c-ares_fuzz_driver_False_deepseek-coder_2'
「4」如果有crash的产生,则有ERROR的字样,所以通过检测返回字符串是否有 ERROR来判断是否有crash。
有个不好的点就是,因为使用的是check_output无法实时显示fuzz的过程,我们可以使用流来实时显示输出。

「5」生成覆盖率报告,这里需要分为三步,
第一步:构建fuzz driver的覆盖率版本(使用--sanitizer coverage,并且这里还需要拉取 Docker 镜像)。总体就是执行了下面两段命令。
docker build -t gcr.io/oss-fuzz/c-ares_base_image \ --file /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/projects/c-ares/Dockerfile \ /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/projects/c-ares docker run --rm \ --privileged --shm-size=2g \ --platform linux/amd64 -i \ -e FUZZING_ENGINE=libfuzzer \ -e SANITIZER=coverage \ -e ARCHITECTURE=x86_64 \ -e PROJECT_NAME=c-ares \ -e HELPER=True \ -e FUZZING_LANGUAGE=c++ \ -v /home/mowen/CKGFuzzer_mowen/docker_shared/:/generated_fuzzer \ -v /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/build/out/c-ares/:/out \ -v /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/build/work/c-ares:/work \ -t gcr.io/oss-fuzz/c-ares \ /bin/bash -c \ 'bash /generated_fuzzer/fuzz_driver/c-ares/scripts/entrancy.sh fix_c-ares_fuzz_driver_False_deepseek-coder_2.cc c-ares && compile'
第二步:使用coverage命令收集并生成覆盖率报告。这里都是基于0SS-FUZZ的。默认生成的报告为HTML形式。
docker run --rm --privileged --shm-size=2g --platform linux/amd64 \ -i \ -e FUZZING_ENGINE=libfuzzer \ -e HELPER=True \ -e FUZZING_LANGUAGE=c++ \ -e PROJECT=c-ares \ -e SANITIZER=coverage \ -e COVERAGE_EXTRA_ARGS= \ -e ARCHITECTURE=x86_64 \ -v /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/build/work/c-ares/fix_c-ares_fuzz_driver_False_deepseek-coder_2_corpus:/corpus/fix_c-ares_fuzz_driver_False_deepseek-coder_2 \ -v /home/mowen/CKGFuzzer_mowen/docker_shared/:/generated_fuzzer \ -v /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/build/out/c-ares:/out \ -t gcr.io/oss-fuzz-base/base-runner \ /bin/bash -c 'coverage fix_c-ares_fuzz_driver_False_deepseek-coder_2'
第三步:将HTML报告转换为可分析文本格式(html2txt()),使用update_coverage_report()更新和比较当前覆盖率。update_coverage_report()调用极为关键,会通过分支覆盖率,判断是否触发新的分支, 如果没有新分支被覆盖,尝试重新 fuzz。
「6」回调尝试提升覆盖率(多轮尝试,默认3次),就是重新完成之前完成的所有步骤:低覆盖率的 API、生成 API 组合、生成新的 fuzz driver 文件、尝试编译新的 fuzz driver 文件并尝试 fix、生成输入 fuzz driver、运行 fuzz driver、生成覆盖率报告、判断是触发新分支。
所有的fuzz操作都是基于0SS-FUZZ,并且是套其他fuzzer进行测试,就是几条命令的执行,这里不展开详细分析,下面重点分析CKGFuzzer是如何回调尝试提升覆盖率的。
def build_and_fuzz_one_file(self, fuzz_driver_file, fix_fuzz_driver_dir=None): # 1. 初始化工作 # 确认 fix fuzz driver 文件夹存在 # 从 fuzzer_name 提取 fuzzer_number,通过 fuzzer_number 获取 api 联合体 if fix_fuzz_driver_dir is None: fix_fuzz_driver_dir = os.path.join(self.directory, f"fuzz_driver/{self.project}/compilation_pass_rag/") if not os.path.exists(fix_fuzz_driver_dir): logger.info(f"No folder {fix_fuzz_driver_dir}") return # 获取 fuzz_driver_file 文件名,不带扩展名 fuzzer_name, _ = os.path.splitext(fuzz_driver_file) # Extract the number from fuzzer_name fuzzer_number = None parts = fuzzer_name.split('_') if len(parts) >= 4: fuzzer_number = int(parts[-1].split('.')[0]) api_combine=self.api_combination[fuzzer_number-1] api_name=api_combine[-1] logger.info(f"Current Fuzzing API Name: {api_name}, its combination: {api_combine}") # 2. 构建 fuzz driver 调用 check_gen_fuzzer.py # build_fuzzer_file -> 删除不需要的文件后,调用执行构建入口sh -> entrancy.sh # build fuzz driver run_args = ["build_fuzzer_file",self.project, "--fuzz_driver_file", fuzz_driver_file] ''' docker exec -u root -it c-ares_check \ /bin/bash -c bash \ /generated_fuzzer/fuzz_driver/c-ares/scripts/entrancy.sh fix_c-ares_fuzz_driver_False_deepseek-coder_2.cc c-ares \ && compile # -u root -> 用 root 用户执行 # -it -> 进入交互式 shell ''' build_fuzzer_result = run(run_args) logger.info(f"compile {fuzz_driver_file}, result {build_fuzzer_result}") # Check if the build was successful if "ERROR" in build_fuzzer_result or "error" in build_fuzzer_result.lower(): # 构建失败则跳过该文件 logger.error(f"Failed to build fuzzer {fuzz_driver_file}. Skipping this file.") self.failed_builds.append(fuzz_driver_file) return else: # 3. 启动 fuzzer # 调用 check_gen_fuzzer.py -> run_fuzzer # If we've reached this point, the build was successful logger.info(f"Successfully built fuzzer {fuzz_driver_file}") # 创建 corpus 文件夹 ,在指定 gen_input 时,该目录之前已经被创建并存放种子 corpus_dir = os.path.join(self.output_dir, f'{fuzzer_name}_corpus') if not os.path.isdir(corpus_dir): # empty corpus os.makedirs(corpus_dir, exist_ok=True) # run fuzzer with libfuzzer run_args = ["run_fuzzer", self.project,"--timeout", self.time_budget, "--fuzz_driver_file", fuzz_driver_file, fuzzer_name,"--fuzzing_llm_dir", self.directory,"--corpus-dir",f"{corpus_dir}"] ''' docker run --rm --privileged --shm-size=2g --platform linux/amd64 \ -i \ -e FUZZING_ENGINE=libfuzzer \ -e SANITIZER=address \ -e RUN_FUZZER_MODE=interactive \ -e FUZZING_LANGUAGE=c++ \ -e HELPER=True \ -e CORPUS_DIR=/tmp/fix_c-ares_fuzz_driver_False_deepseek-coder_2_corpus \ -v /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/build/work/c-ares/fix_c-ares_fuzz_driver_False_deepseek-coder_2_corpus:/tmp/fix_c-ares_fuzz_driver_False_deepseek-coder_2_corpus \ -v /home/mowen/CKGFuzzer_mowen/docker_shared/:/generated_fuzzer \ -v /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/build/out/c-ares:/out \ -t gcr.io/oss-fuzz-base/base-runner \ /bin/bash -c 'timeout 1m run_fuzzer fix_c-ares_fuzz_driver_False_deepseek-coder_2' ''' run_fuzzer_result = run(run_args) logger.info(f"run_fuzzer {fuzz_driver_file}, result {run_fuzzer_result}") # 4. 检查是否有 crash if "ERROR" in run_fuzzer_result: logger.info("Crash detected. Analyzing...") error_index = run_fuzzer_result.index("ERROR") crash_info = run_fuzzer_result[error_index:] # 提取错误信息 # Extract only the error message # 分析 crash 并保存分析结果 is_api_bug, crash_category, crash_analysis = self.crash_analyzer.analyze_crash(crash_info, f"{fix_fuzz_driver_dir}/{fuzz_driver_file}", api_combine) save_crash_analysis(self.fuzz_project_dir, fuzz_driver_file, is_api_bug, crash_category, crash_analysis, crash_info,f"{fix_fuzz_driver_dir}/{fuzz_driver_file}") # build fuzzer with coverage to collect the coverage reports # 5. 生成覆盖率报告 # 编译 fuzzer 构建环境 run_args=['build_fuzzers',self.project, "--sanitizer", "coverage", "--fuzzing_llm_dir", self.directory, "--fuzz_driver_file", fuzz_driver_file] ''' docker build -t gcr.io/oss-fuzz/c-ares_base_image \ --file /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/projects/c-ares/Dockerfile \ /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/projects/c-ares docker run --rm \ --privileged --shm-size=2g \ --platform linux/amd64 -i \ -e FUZZING_ENGINE=libfuzzer \ -e SANITIZER=coverage \ -e ARCHITECTURE=x86_64 \ -e PROJECT_NAME=c-ares \ -e HELPER=True \ -e FUZZING_LANGUAGE=c++ \ -v /home/mowen/CKGFuzzer_mowen/docker_shared/:/generated_fuzzer \ -v /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/build/out/c-ares/:/out \ -v /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/build/work/c-ares:/work \ -t gcr.io/oss-fuzz/c-ares \ /bin/bash -c \ 'bash /generated_fuzzer/fuzz_driver/c-ares/scripts/entrancy.sh fix_c-ares_fuzz_driver_False_deepseek-coder_2.cc c-ares && compile' ''' build_fuzzers_result = run(run_args) logger.info(f"build coverage {self.project}, result {build_fuzzers_result}") # compute coverage # 执行 coverage 生成报告 run_args=['coverage', self.project, "--fuzz-target",fuzzer_name, "--fuzz_driver_file", fuzz_driver_file,"--corpus-dir", f"{corpus_dir}", "--fuzzing_llm_dir", self.directory,"--no_serve"] ''' docker run --rm --privileged --shm-size=2g --platform linux/amd64 \ -i \ -e FUZZING_ENGINE=libfuzzer \ -e HELPER=True \ -e FUZZING_LANGUAGE=c++ \ -e PROJECT=c-ares \ -e SANITIZER=coverage \ -e COVERAGE_EXTRA_ARGS= \ -e ARCHITECTURE=x86_64 \ -v /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/build/work/c-ares/fix_c-ares_fuzz_driver_False_deepseek-coder_2_corpus:/corpus/fix_c-ares_fuzz_driver_False_deepseek-coder_2 \ -v /home/mowen/CKGFuzzer_mowen/docker_shared/:/generated_fuzzer \ -v /home/mowen/CKGFuzzer_mowen/fuzzing_llm_engine/build/out/c-ares:/out \ -t gcr.io/oss-fuzz-base/base-runner \ /bin/bash -c 'coverage fix_c-ares_fuzz_driver_False_deepseek-coder_2' ''' coverage_result = run(run_args) logger.info(f"coverage {fuzz_driver_file}, result {coverage_result}") logger.info("Computing current coverage...") # collect coverage reports # 计算覆盖率 html2txt(f"{self.coverage_dir}{fuzzer_name}{self.report_target_dir}",f"{self.report_dir}{fuzzer_name}/") # 更新覆盖率报告 update_successful, current_line_coverage, total_lines, covered_lines, current_branch_coverage, total_branches, covered_branches, file_coverages = update_coverage_report( f"{self.report_dir}merge_report", f"{self.report_dir}{fuzzer_name}/" ) # 如果第一次更新覆盖率 if self.covered_lines==0 and self.covered_branches==0: self.covered_lines = covered_lines self.covered_branches = covered_branches logger.info(f"Current covered lines: {self.covered_lines}, Total lines: {total_lines}") logger.info(f"Current covered branches: {self.covered_branches}, Total branches: {total_branches}") # 更新 API 使用计数 self.update_api_usage_count(api_combine) # 多次合并 else: # 有新分支被覆盖,更新记录 if update_successful: self.covered_lines = covered_lines self.covered_branches = covered_branches logger.info(f"Coverage updated. Current covered lines: {self.covered_lines}, Total lines: {total_lines}") logger.info(f"Current covered branches: {self.covered_branches}, Total branches: {total_branches}") self.update_api_usage_count(api_combine) else: # 如果没有新分支被覆盖,尝试重新 fuzz i=0 while not update_successful and i < self.max_itr_fuzz_loop: if i == 0: current_api_combine = api_combine else: current_api_combine = new_api_combine logger.info(f"No new branches covered. Regenerating API combination. Iteration: {i+1}") # 获取低覆盖率的 API low_coverage_apis = self.analyze_low_coverage_files(current_branch_coverage,file_coverages) logger.info(f"Low coverage APIs: {low_coverage_apis}") # 生成新的 API 组合 new_api_combine = self.planner.generate_single_api_combination(api_name, current_api_combine, low_coverage_apis,) logger.info(f"New API Combination: {new_api_combine}") # 生成新的 fuzz driver 文件 self.fuzz_gen.generate_single_fuzz_driver(new_api_combine, fuzz_driver_file, self.api_code, self.api_summary, self.fuzz_gen_code_output_dir) # 尝试编译新的 fuzz driver 文件并尝试 fix compilation_success = self.compilation_fix_agent.single_fix_compilation(fuzz_driver_file, self.fuzz_gen_code_output_dir, self.project) if not compilation_success: # 如果 fix 失败则退出 logger.info(f"Compilation check failed after max iterations, continue to fuzzing") os.remove(f"{fix_fuzz_driver_dir}/{fuzz_driver_file}") return # 生成输入 fuzz driver self.input_gen.generate_input_fuzz_driver(f"{fix_fuzz_driver_dir}/{fuzz_driver_file}") # 构建并运行 fuzz driver run_args = ["build_fuzzer_file",self.project, "--fuzz_driver_file", fuzz_driver_file] build_fuzzer_result = run(run_args) logger.info(f"compile {fuzz_driver_file}, result {build_fuzzer_result}") if "ERROR" in build_fuzzer_result or "error" in build_fuzzer_result.lower(): logger.error(f"Failed to build fuzzer {fuzz_driver_file}. Skipping this file.") continue # 运行 fuzz driver run_args = ["run_fuzzer", self.project,"--timeout", self.time_budget, "--fuzz_driver_file", fuzz_driver_file, fuzzer_name,"--fuzzing_llm_dir", self.directory,"--corpus-dir",f"{corpus_dir}"] run_fuzzer_result = run(run_args) logger.info(f"run_fuzzer {fuzz_driver_file}, result {run_fuzzer_result}") # 是否生成 crash if "ERROR" in run_fuzzer_result: logger.info("Crash detected. Analyzing...") error_index = run_fuzzer_result.index("ERROR") crash_info = run_fuzzer_result[error_index:] is_api_bug, crash_category, crash_analysis = self.crash_analyzer.analyze_crash(crash_info, f"{fix_fuzz_driver_dir}/{fuzz_driver_file}", current_api_combine) save_crash_analysis(self.fuzz_project_dir, fuzz_driver_file, is_api_bug, crash_category, crash_analysis, crash_info,f"{fix_fuzz_driver_dir}/{fuzz_driver_file}") # build fuzzer with coverage to collect the coverage reports run_args=['build_fuzzers',self.project, "--sanitizer", "coverage", "--fuzzing_llm_dir", self.directory, "--fuzz_driver_file", fuzz_driver_file] build_fuzzers_result = run(run_args) logger.info(f"build coverage {self.project}, result {build_fuzzers_result}") run_args=['coverage',self.project, "--fuzz-target",fuzzer_name, "--fuzz_driver_file", fuzz_driver_file,"--corpus-dir", f"{corpus_dir}", "--fuzzing_llm_dir", self.directory,"--no_serve"] coverage_result = run(run_args) logger.info(f"coverage {fuzz_driver_file}, result {coverage_result}") html2txt(f"{self.coverage_dir}{fuzzer_name}{self.report_target_dir}",f"{self.report_dir}{fuzzer_name}/") update_successful, current_line_coverage, total_lines, covered_lines,current_branch_coverage, total_branches, covered_branches, file_coverages = update_coverage_report( f"{self.report_dir}merge_report", f"{self.report_dir}{fuzzer_name}/" ) if update_successful: self.covered_lines = covered_lines self.covered_branches = covered_branches logger.info(f"Coverage updated. Current covered lines: {self.covered_lines}, Total lines: {total_lines}") logger.info(f"Current covered branches: {self.covered_branches}, Total branches: {total_branches}") self.planner.update_api_usage_count(new_api_combine) # Update api_combine with new_api_combine self.api_combination[fuzzer_number-1] = new_api_combine # Save updated api_combine to JSON file json_file_path = self.fuzz_project_dir+"agents_results/api_combine.json" with open(json_file_path, 'w') as f: json.dump(self.api_combination, f, indent=2) logger.info(f"Updated api_combine saved to {json_file_path}") return i += 1 # Update api_combine with new_api_combine even if max iterations reached self.api_combination[fuzzer_number-1] = new_api_combine # Save updated api_combine to JSON file # 保存 api_combination json_file_path = self.fuzz_project_dir+"agents_results/api_combine.json" with open(json_file_path, 'w') as f: json.dump(self.api_combination, f, indent=2) self.planner.update_api_usage_count(new_api_combine) logger.info(f"Updated api_combine saved to {json_file_path} after reaching max iterations") logger.info("Max iterations reached.") logger.info(f"Coverage updated. Current covered lines: {self.covered_lines}, Total lines: {total_lines}") logger.info(f"Current covered branches: {self.covered_branches}, Total branches: {total_branches}")
通过0SS-FUZZ提供的Coverage Report是HTML形式的,方便用户看,但是需要处理判断数据就需要提取数据。 所以html2txt()函数主要作用就是把HTML中的数据提取出来。
html2txt

「1」遍历所有符合条件的HTML文件(.c.html, .cc.html, .cpp.html),且不包含 "fuzz_driver" 关键词的文件。使用BeautifulSoup解析HTML内容,因为覆盖率信息一般保存在表格中,所以会查找所有的table元素,遍历每一行把数据提取出来,将提取后的文本写入到对应的txt文件中。
目录结构如下,每个target_fuzz都会有一个专门的文件,这里比较重要的是merge_report,该目录为覆盖率合并目录,把所有target_fuzz的覆盖率信息全部合并。这个文件夹是之后回调的关键。
「1」这里的参数merge_dir就是之前提到的累计合并覆盖率报告目录,new_report_dir为每次单个target_fuzz生成的覆盖率报告。
「2」会先创建临时目录temp_dir,将new_report_dir和merge_dir在临时目录temp_dir中合并。再进行temp_dir和merge_dir的覆盖率比较,以此判断新产生的覆盖率是否比之前已有数据更全面,分支更多。
「3」调用calculate_line_coverage()用来收集行覆盖率、调用calculate_branch_coverage()用来收集分支覆盖率。calculate_files_branch_coverages计算每个文件的分支覆盖率。这里的行覆盖率就是代码行数,分支覆盖率就是分支次数(分支:if,switch等)。
「4」判断是否有新的分支被覆盖(核心判断标准),如果发现新的分支被覆盖,更新 merge_dir(用临时目录覆盖原目录),并返回True。返回的bool决定之后是否回调然后重新fuzz。
def update_coverage_report(merge_dir, new_report_dir): ''' 参数: merge_dir: 当前累计的合并覆盖率报告目录 new_report_dir: 新生成的覆盖率报告目录 返回值: 是否更新成功 (bool) 最新行覆盖率、总行数、已覆盖行数 最新分支覆盖率、总分支数、已覆盖分支数 每个文件的分支覆盖率统计信息 ''' # 检查覆盖率提取的新目录是否不存在 if not os.path.exists(new_report_dir): logger.info(f"The new report directory {new_report_dir} does not exist.") return False, 0, 0, 0, 0, 0, 0, {} # 检查目录是否空 # Check if new_report_dir is empty if not os.listdir(new_report_dir): logger.info(f"The new report directory {new_report_dir} is empty.") return False, 0, 0, 0, 0, 0, 0, {} # Create merge_dir if it doesn't exist # 创建合并报告目录 if not os.path.exists(merge_dir): os.makedirs(merge_dir) logger.info(f"Created merge directory: {merge_dir}") # 使用临时目录处理合并过程 with tempfile.TemporaryDirectory() as temp_dir: # Copy the current merge report to the temporary directory # 将当前的 merge_dir 到 临时目录 shutil.copytree(merge_dir, temp_dir, dirs_exist_ok=True) # Update the temporary directory with the new report # 将新报告目录中的所有 txt 文件合并进临时目录 for filename in os.listdir(new_report_dir): if filename.endswith('.txt'): temp_file = os.path.join(temp_dir, filename) new_file = os.path.join(new_report_dir, filename) # 如果临时目录中已存在该文件,进行内容合并 if os.path.exists(temp_file): update_file(temp_file, new_file) else: # 否则直接复制新文件 shutil.copy2(new_file, temp_file) # Calculate coverages for the original merge directory and the temporary directory # 分别计算 原始、临时 的行覆盖率 old_line_cov, old_total_lines, old_covered_lines = calculate_line_coverage(merge_dir) new_line_cov, new_total_lines, new_covered_lines = calculate_line_coverage(temp_dir) # 分别计算 原始、临时 的分支覆盖率 old_branch_cov, old_total_branches, old_covered_branches = calculate_branch_coverage(merge_dir) new_branch_cov, new_total_branches, new_covered_branches = calculate_branch_coverage(temp_dir) # 计算每个文件的分支覆盖率 file_coverages = calculate_files_branch_coverages(temp_dir) # 判断是否有新的分支被覆盖(核心判断标准) # 覆盖分支数 new > 旧覆盖分支数 old new_branches_covered = new_covered_branches > old_covered_branches if new_branches_covered: # 如果发现新的分支被覆盖,更新 merge_dir(用临时目录覆盖原目录) shutil.rmtree(merge_dir) shutil.copytree(temp_dir, merge_dir) logger.info(f"New branches covered. Current covered branches: {new_covered_branches}, Previous covered branches: {old_covered_branches}. Merge report updated.") return True, new_line_cov, new_total_lines, new_covered_lines, new_branch_cov, new_total_branches, new_covered_branches, file_coverages else: logger.info(f"No new branches covered. Current covered branches: {new_covered_branches}, Previous covered branches: {old_covered_branches}. Merge report not updated.") return False, old_line_cov, old_total_lines, old_covered_lines, old_branch_cov, old_total_branches, old_covered_branches, file_coverages
update_coverage_report
「1」计算行覆盖率还是比较简单的,遍历文件夹下面的所有txt文件,提取出代码行定位 + 覆盖次数 + 代码,如果覆盖次数不是0,说明这一行被覆盖了,就累加起来。
「2」这里行覆盖率不同于覆盖次数,无论覆盖次数为多少,只要被覆盖到就累加1,这样的好处就是规避了覆盖次数带来的不准确性。
「3」共返回三个字段total_lines(总行数)、covered_lines(覆盖行数)、coverage( 行覆盖率==covered_lines / total_lines )。
def calculate_line_coverage(merge_dir): ''' 统计被符号的行数 返回:行覆盖率、总行数、被覆盖行数 ''' total_lines = 0 # 总行数 covered_lines = 0 # 覆盖行数 # 遍历所有 txt 文件 for filename in os.listdir(merge_dir): if filename.endswith('.txt'): file_path = os.path.join(merge_dir, filename) with open(file_path, 'r') as f: for line in f: # 代码行定位 + 覆盖次数 + 代码 parts = line.split('\t') if len(parts) >= 2: count_str = parts[1].strip() if count_str and not count_str.startswith('Source'): total_lines += 1 # 如果覆盖次数不是 0,说明这一行被覆盖了 if count_str != '0': covered_lines += 1 # print(f"total_lines: {total_lines}") # print(f"covered_lines: {covered_lines}") if total_lines > 0: coverage = covered_lines / total_lines return coverage,total_lines,covered_lines else: return 0,0,0
「1」计算分支覆盖率的逻辑和行覆盖率大致一致,只是多了一个identify_branches(),用正则判断是否为分支(if,switch等)。
「2」也是返回三个字段coverage( 分支覆盖率 == total_branches/ covered_branches )、total_branches(总分支数)、covered_branches(覆盖分支数)
def calculate_branch_coverage(merge_dir): ''' 计算分支(if,switch等)覆盖度 返回 : 分支覆盖率,总分支数,覆盖分支数 ''' total_branches = 0 # 总分支数 covered_branches = 0 # 覆盖分支数 # 没调用啊 def parse_count(count_str): if count_str.endswith('k') or count_str.endswith('K'): return int(float(count_str[:-1]) * 1000) elif count_str.endswith('m') or count_str.endswith('M'): return int(float(count_str[:-1]) * 1000000) return int(float(count_str)) # Use float() to handle decimal points for filename in os.listdir(merge_dir): if filename.endswith('.txt'): file_path = os.path.join(merge_dir, filename) with open(file_path, 'r') as f: for line_num, line in enumerate(f, 1): parts = line.split('\t') # 代码行定位 覆盖次数 代码 if len(parts) >= 3: count_str = parts[1].strip() code = parts[2].strip() # 该行是否包含分支结构( if、for 等) branches = identify_branches(code, line_num) for branch in branches: total_branches += 1 if count_str and count_str != '0': covered_branches += 1 if total_branches > 0: coverage = covered_branches / total_branches return coverage, total_branches, covered_branches else: return 0, 0, 0
计算目录下所有文件的分支覆盖率
「1」遍历directory下所有txt文件,对单个文件进行分支覆盖率的判断,判断逻辑和之前分析的计算分支覆盖率一致,计算结果采用字典处理。
calculate_line_coverage
calculate_branch_coverage
calculate_files_branch_coverages

